3.2 Design of Experiments
An experiment is a study in which we actually do something to people, animals, or objects in order to observe the response. Here is the basic vocabulary of experiments.
Because the purpose of an experiment is to reveal the response of one variable to changes in one or more other variables, the distinction between explanatory and response variables is important. The explanatory variables in an experiment are often called factors. Many experiments study the joint effects of several factors. In such an experiment, each treatment is formed by combining a specific value (often called a level) of each of the factors.
Example 3.11 Are smaller class sizes better?
Do smaller classes in elementary school really benefit students in areas such as scores on standard tests, staying in school, and going on to college? We might do an observational study that compares students who happened to be in smaller classes with those who happened to be in larger classes in their early school years. Small classes are expensive, and they are more common in schools that serve richer communities. Students in small classes tend to also have other advantages: their schools have more resources, their parents are better educated, and so on. Confounding makes it impossible to isolate the effects of small classes.
The Tennessee STAR program was an experiment on the effects of class size. It has been called “one of the most important educational investigations ever carried out.” The subjects (experimental units) were 6385 students who were beginning kindergarten. Each student was assigned to one of three treatments: regular class (22 to 25 students) with one teacher, regular class (22 to 25 students) with a teacher and a full-time teacher’s aide, and small class (13 to 17 students) with one teacher. These treatments are levels of a single factor, the type of class. The students stayed in the same type of class for four years and then all returned to regular classes. In later years, students from the small classes had higher scores on the outcomes, standard tests. The benefits of small classes were greatest for minority students.10
Example 3.11 illustrates the big advantage of experiments over observational studies. In principle, experiments can give good evidence for causation. In an experiment, we study the specific factors we are interested in while controlling the effects of lurking variables. All the students in the Tennessee STAR program followed the usual curriculum at their schools. Because students were assigned to different class types within their schools, school resources and family backgrounds were not confounded with class type. The only systematic difference was the type of class. When students from the small classes did better than those in the other two types, we can be confident that class size made the difference.
Example 3.12 Repeated exposure to advertising.

What are the effects of repeated exposure to an advertising message? The answer may depend both on the length of the ad and on how often it is repeated. An experiment investigated this question using undergraduate students as subjects. All subjects viewed a 40-minute television program that included ads for a digital camera. Some subjects saw a 30-second commercial; others, a 90-second version. The same commercial was shown either one, three, or five times during the program.
This experiment has two factors: length of the commercial, with two levels, and repetitions, with three levels. The six combinations of one level of each factor form six treatments. Figure 3.2 shows the layout of the treatments. After viewing the TV program, all the subjects answered questions about their recall of the ad, their attitude toward the camera, and their intention to purchase it. These are the outcomes.
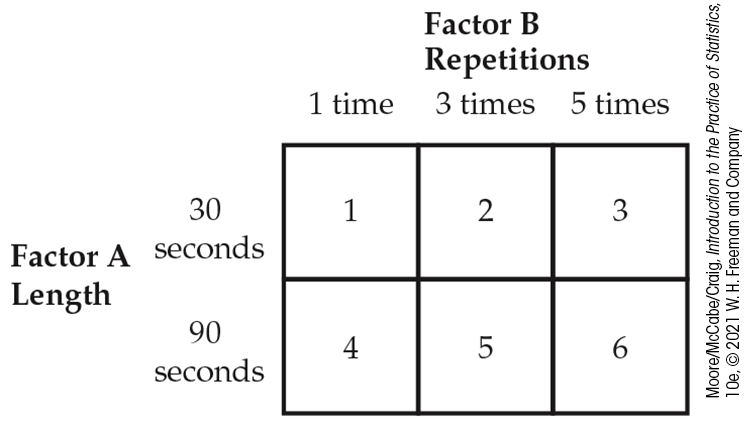
Figure 3.2 The treatments in the study of advertising, Example 3.12. Combining the levels of the two factors forms six treatments.
Example 3.12 shows how experiments allow us to study the combined effects of more than one factor. The interaction of several factors can produce effects that cannot be predicted from looking at the effects of each factor alone. Perhaps longer commercials increase interest in a product, and more commercials also increase interest, but if we both make a commercial longer and show it more often, viewers get annoyed, and their interest in the product drops. The two-factor experiment in Example 3.12 will help us find out. The analysis of this experiment is discussed in Chapter 13 (page 651).
Check-in
-
3.12 The post-lunch dip and almonds. Research has shown that after lunch people experience a decrease in alertness and other cognitive functions. Participants in a 12-week weight loss program were randomly assigned to receive an almond-enriched energy-restricted diet or a nut-free energy-restricted diet, 43 participants to each diet. At the end of the 12-week period several tests were used to measure cognitive functions.11 Explain why this study is an experiment and identify the experimental units, the treatments, and the response variables. Describe the factor and its levels.
-
3.13 Does echinacea reduce the severity of the common cold? In a study designed to evaluate the benefits of taking echinacea when you have a cold, 719 patients were randomly divided into four groups. The groups were (1) no pills, (2) pills that had no echinacea, (3) pills that had echinacea but the subjects did not know whether or not the pills contained echinacea, and (4) pills that had echinacea and the bottle containing the pills stated that the contents included echinacea. The outcome was a measure of the severity of the cold.12 Identify the experimental units, the treatments, and the outcome. Describe the factor and its levels. The study subjects were aged 12 to 80 years. To what extent do you think the results of this experiment can be generalized to young children?
Comparative experiments
Laboratory experiments in science and engineering often have a simple design with only a single treatment, which is applied to all experimental units. The design of such an experiment can be outlined as
For example, we may subject a beam to a load (treatment) and measure its deflection (observation). We rely on the controlled environment of the laboratory to protect us from lurking variables. When experiments are conducted outside the laboratory or with living subjects, such simple designs often yield complicated data. That is, we cannot tell whether the response was due to the treatment or to lurking variables.
Example 3.13 Will a new treatment reduce knee pain?
A study designed to examine the effect of a new treatment to reduce knee pain asked patients to rate their knee pain before and after receiving the new treatment. The change in the pain scores was analyzed.
The knee pain experiment of Example 3.13 was poorly designed to evaluate the effect of the new treatment. Perhaps pain would have decreased after the treatment because patients responded positively to the concern and attention given them by the people giving the treatment.
In medical settings, this phenomenon is called the placebo effect. In medicine, a placebo is a dummy treatment, such as a sugar pill. People can respond favorably to personal attention or to any treatment that they hope will help them.
The knee pain experiment gave inconclusive results because the effect of the treatment was confounded with other factors that could have had an effect on the pain, such as time, the season or the weather, or the placebo effect. The best way to avoid confounding is to do a comparative experiment.
Example 3.14 A treatment for arthritis in the knee.
A study enrolled 244 participants with primary knee osteoarthritis
(arthritis of the knee) to evaluate the effect of a new treatment,
NIV-711, designed to reduce the knee pain for these patients. Knee
pain was measured using a numerical rating scale (NRS). The NRS was
measured at the beginning of the study (baseline) and at the end of
the study. The researchers were primarily interested in the change
in the NRS from baseline to the end of the study. Participants were
randomized to receive a low dose of NIV-711
In medical settings, it is standard practice to randomly assign patients either to one or more treatment groups or a control group. The effects of a treatment are evaluated by making a comparison with the control group. For a comparison to be valid, the conditions experienced by subjects in each treatment group and the control group should be identical except that the treatment groups receive the product or products that are being evaluated.
Example 3.15 Control group for the knee pain experiment.
In the knee pain experiment of Example 3.14, the control group received the placebo treatment.
![]() Uncontrolled experiments (that is, experiments that don’t include a
control group) in medicine and the behavioral sciences can be
dominated by such influences as the details of the experimental
arrangement, the selection of subjects, and the placebo effect.
The result is often bias.
Uncontrolled experiments (that is, experiments that don’t include a
control group) in medicine and the behavioral sciences can be
dominated by such influences as the details of the experimental
arrangement, the selection of subjects, and the placebo effect.
The result is often bias.
Example 3.16 The knee pain experiment without the control group.
The knee pain experiment of Example 3.13 has no control group. The change from before to after the treatment could be due to other conditions that changed during this time period—for example, the placebo effect or being seen by a doctor. The study is not valid and is potentially biased because we have no way of assessing or controlling for these conditions.
Uncontrolled studies can give new treatments a much higher success rate than proper comparative experiments do. Well-designed experiments usually compare several treatments.
Example 3.17 Consider the subjects.
The knee pain experiment of Example 3.14 was conducted at four sites in four European countries (Bulgaria, Georgia, Germany, and Moldavia). The results are potentially biased for estimating effects in Canada, China, and Kenya because no subjects from these non-European countries were evaluated in the experiment.
Check-in
-
3.14 Can magnets ease the pain of migraine headaches? A study was designed to evaluate the effect of the Cerena Transcranial Magnetic Stimulator14 to treat pain associated with migraine headaches. The subjects were 100 college students who had frequent migraine headaches. The students were instructed to use the cranial stimulator when they had a headache and to report whether there was substantial relief from headache pain within an hour.
Explain why this study is biased.
-
How would you change the study to remove the bias? Explain your answer.
-
3.15 Are the teacher evaluations biased? The evaluations of two instructors by their students are compared when it is time to determine raises for the coming year. One instructor teaches classes with small enrollments designed primarily for graduate students in the department. The other teaches classes with very large enrollments designed for first-year students majoring in other fields. Discuss the possibility of bias in this context.
Randomization
An experimental design first describes the response variable or variables, the factors (explanatory variables), and the treatments, with comparison as the leading principle. Figure 3.2 (page 162) illustrates this aspect of the design of a study of response to advertising. The second aspect of experimental design is how the experimental units are assigned to the treatments. Comparison of the effects of several treatments is valid only when all treatments are applied to similar groups of experimental units. If one corn variety is planted on more fertile ground or if one cancer drug is given to more seriously ill patients, comparisons among treatments are meaningless. If groups assigned to treatments are quite different in a comparative experiment, we should be concerned that our experiment will be biased. How can we assign experimental units to treatments in a way that is fair to all treatments?
Experimenters sometimes attempt to match groups with elaborate balancing acts. Medical researchers, for example, try to match the patients in a “new drug” experimental group and a “standard drug” control group by age, sex, physical condition, smoker or not, and so on. Matching can be helpful, but often there are too many lurking variables that might affect the outcome.
Some important variables, such as how advanced a cancer patient’s disease is, are so subjective that they can’t be measured. In other cases, an experimenter might unconsciously bias a study by assigning those patients who seemed the sickest to a promising new treatment in the (unconscious) hope that it would help them.
The statistician’s remedy is to rely on chance to make an assignment that does not depend on any characteristic of the experimental units and that does not rely on the judgment of the experimenter in any way. The use of chance can be combined with matching, but the simplest experimental design creates groups by chance alone. Here is an example.
Example 3.18 Which smartphone should be marketed?

Two teams have each prepared a prototype for a new smartphone. Before deciding which one will be marketed, the smartphones will be evaluated by college students. Forty students will each receive a new phone. They will use it for two weeks and then answer some questions about how well they like the phone. The 40 students will be randomized, with 20 receiving each phone.
This experiment has a single factor (prototype) with two levels. The researchers must divide the 40 student subjects into two groups of 20. To do this in a completely unbiased fashion, put the names of the 40 students in a hat, mix them up, and draw 20. These students will receive Phone 1, and the remaining 20 will receive Phone 2. Figure 3.3 outlines the design of this experiment.
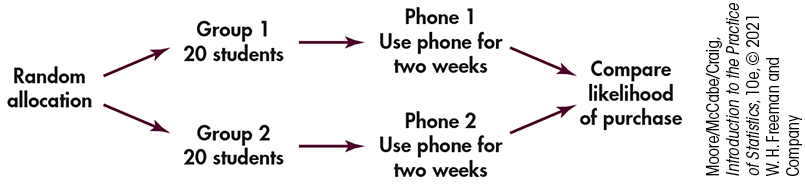
Figure 3.3 Outline of a randomized comparative experiment, Example 3.18.
The use of chance to divide experimental units into groups is called randomization. The design in Figure 3.3 combines comparison and randomization to arrive at the simplest randomized comparative design. This “flowchart” outline presents all the essentials: randomization, the sizes of the groups and which treatment they receive, and the response variable. There are, as we will see later, statistical reasons for using treatment groups that are about equal in size.
Check-in
-
3.16 Diagram the echinacea experiment. Refer to Exercise 3.5 (page 161). Draw a diagram similar to Figure 3.3 that describes the experiment.
-
3.17 Diagram the knee pain experiment. Draw a diagram similar to Figure 3.3 that describes the experiment of Example 3.14 (page 167).
Randomized comparative experiments
The logic behind the randomized comparative design in Figure 3.3 is as follows:
-
Randomization produces two groups of subjects that we expect to be similar in all respects before the treatments are applied.
-
Comparative design helps ensure that influences other than the characteristics of the smartphone operate equally on both groups.
-
Therefore, differences in the satisfaction with the smartphone must be due either to the characteristics of the phone or to the chance assignment of subjects to the two groups.
That “either-or” deserves more comment. We cannot say that all the difference in the satisfaction with the two smartphones is caused by the characteristics of the phones. There would be some difference even if both groups used the same phone. Some students would be more likely to be highly favorable of any new phone. Chance can assign more of these students to one of the phones so that there is a chance difference between the groups. We would not trust an experiment with just one subject in each group, for example. The results would depend too much on which phone got lucky and received the subject who was more likely to be highly satisfied. If we assign many students to each group, however, the effects of chance will average out. There will be little difference in the satisfaction between the two groups unless the phone characteristics cause a difference. “Use enough subjects to reduce chance variation” is the last of the three big ideas of statistical design of experiments.
Example 3.19 Principles for the knee pain experiment.
Refer to the knee pain experiment in Example 3.14 (page 167). The experiment compared three treatments: low dose NIV-711, high dose NIV-711, and a placebo. The patients were randomized to the three treatments. There were 244 participants in the study. Note that the numbers in the three treatments were not exactly equal. This was probably due to some patients not completing the study.
How to randomize
![]() The idea of randomization is to assign subjects to treatments by
drawing names from a hat. In practice, experimenters use software to
carry out randomization. For example, most statistical software can
choose 5 out of a list of 10 at random. The list might contain the
names of 10 human subjects to be randomly assigned to two groups. The
5 chosen form one group, and the 5 that remain form the second group.
The Simple Random Sample applet on the text website makes it
particularly easy to choose treatment groups at random.
The idea of randomization is to assign subjects to treatments by
drawing names from a hat. In practice, experimenters use software to
carry out randomization. For example, most statistical software can
choose 5 out of a list of 10 at random. The list might contain the
names of 10 human subjects to be randomly assigned to two groups. The
5 chosen form one group, and the 5 that remain form the second group.
The Simple Random Sample applet on the text website makes it
particularly easy to choose treatment groups at random.
When we randomize, we first give a label to each item in the collection of items to be randomized. The label could be the name of a subject in a clinical study or simply a numerical identification number. To illustrate randomization methods, let’s randomize 10 subjects for a study that will compare a treatment with a placebo control. We will randomly select the 5 subjects for the treatment group, and the remaining subjects will receive the placebo. We start by labeling the subjects with the numbers 1 through 10.
Randomization using software
![]()
Figure 3.4 summarizes one way to do the randomization using Excel. We start with a spreadsheet that has 10 rows corresponding to 10 subjects to be randomized to treatment or placebo. The process is essentially the same as writing the labels on a deck of 10 cards. We then shuffle the cards and deal 5 cards to form the treatment group.
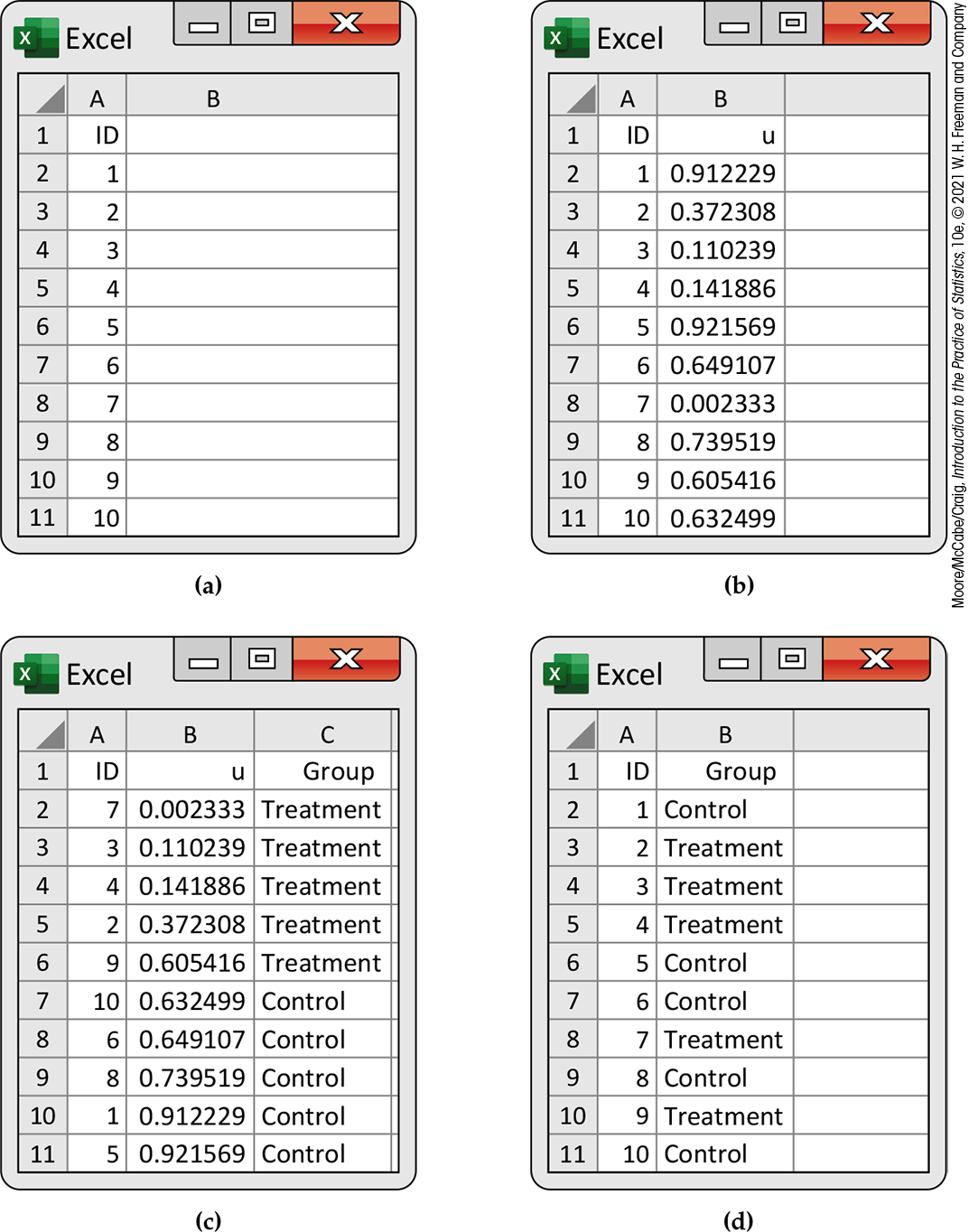
Figure 3.4 Randomization of 10 experimental units using an Excel spreadsheet, Example 3.20: (a) labels; (b) random numbers; (c) sorted list of labels; (d) labels with group assignments.
Example 3.20 Using software for the randomization.
The basic idea is that we generate a random variable from a uniform distribution (see Exercise 1.73, page 64) for each subject. In Excel, we use the RAND() function for this step. Then we sort the spreadsheet by the column with the uniform numbers and select the first five labels to be the treatment group and the remaining labels to be the placebo controls.
Here are the details: First create a data set with the numbers 1 to 10 in the first column. See Figure 3.4(a). Then we use RAND() to generate 10 random numbers in the second column. See Figure 3.4(b). Finally, we sort the data set based on the numbers in the second column. See Figure 3.4(c). The first five labels (7, 3, 4, 2, and 9) will receive the treatment. The remaining five labels (10, 6, 8, 1, and 5) will receive the placebo control.
If you want to save the random numbers that you generated in your file, you should copy them to another column using the “Paste Values” option before you perform the sort. Note that we have added a column called Group to the spreadsheet, which lists the group to which each subject is assigned. With this variable included, we can now sort the file on ID and delete the column with the random numbers. The result is shown in Figure 3.4(d). The spreadsheet in this form can now be used as a template for entering data.
Randomization using random digits
You can randomize without software by using a table of random digits. Thinking about random digits helps you to understand randomization even if you will use software in practice. Table B at the back of the book is a table of random digits.
You can think of Table B as the result of asking an assistant (or a computer) to mix the digits 0 to 9 in a hat, draw one, then replace the digit drawn, mix again, draw a second digit, and so on. It saves us the work of mixing and drawing when we need to randomize. Table B begins with the digits 19223950340575628713. To make the table easier to read, the digits appear in groups of five and in numbered rows. The groups and rows have no meaning; the table is just a long list of digits having Properties 1 and 2 described earlier.
Our goal is to use random digits for experimental randomization. We need the following facts about random digits, which are consequences of Properties 1 and 2:
-
Any pair of random digits has the same chance of being any of the 100 possible pairs: 00, 01, 02, . . . , 98, 99.
-
Any triple of random digits has the same chance of being any of the 1000 possible triples: 000, 001, 002, . . . , 998, 999.
-
. . . and so on for groups of four or more random digits.
Example 3.21 Randomize the subjects.
Let’s use random digits to do the randomization that we performed using Excel in Example 3.20. Because the labels range from 1 to 10, we can use two digits for our labels
when we select random digits from Table B. We could also change our labels to 0 through 9, and then we would only need to use single digits from Table B.
Start anywhere in Table B and read two-digit groups. Suppose we begin at line 175, which is
The first 10 two-digit groups in this line are
Each of these two-digit groups is a label. The labels 00 and 11 to 99 are not used in this example, so we ignore them. The first 10 labels between 01 and 10 that we encounter in the table choose subjects who will receive the treatment. Of the first 10 labels in line 175, we ignore seven because they are too high (over 10). The others are 01, 10, and 06. Continue across line 175 and 176 and verify that the next two subjects selected correspond to labels 03 and 04. Our randomization has selected subjects 1, 3, 4, 6, and 10 to receive the treatment. The remaining subjects, 2, 5, 7, 8, and 9, will receive the placebo control.
When all experimental units are allocated at random among all treatments, as in Examples 3.20 (page 168) and 3.21, the experimental design is known as a completely randomized design. Completely randomized designs can compare any number of treatments. The treatments can be formed by levels of a single factor or by more than one factor.
Example 3.22 Randomization for the TV commercial experiment.
Figure 3.2 (page 162) displays six treatments formed by the two factors in an experiment on response to a TV commercial. Suppose that you have 150 students who are willing to serve as subjects. You must assign 25 students at random to each group. Figure 3.5 outlines the completely randomized design.
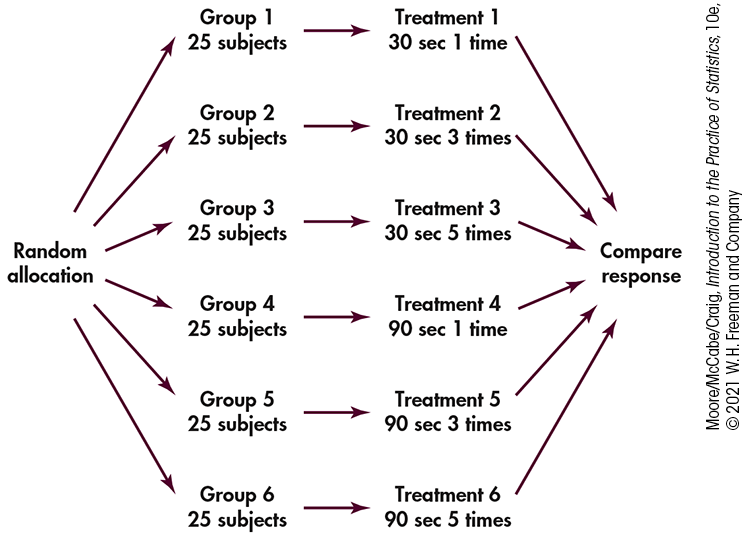
Figure 3.5 Outline of a completely randomized design comparing six treatments, Example 3.22.
To carry out the random assignment, label the 150 students 001 to 150. (Three digits are needed to label 150 subjects.) Using Excel, you would generate a uniform random variable for each label and sort the file as in Example 3.20. The first 25 students in this sorted file will receive Treatment 1, the next 25 will receive Treatment 2, etc.
Using random digits, you could enter Table B and read three-digit groups until you have selected 25 students to receive Treatment 1 (a 30-second ad shown once). If you start at line 140, the first few labels for Treatment 1 subjects are 129, 048, and 003.
Continue in Table B to select 25 more students to receive Treatment 2 (a 30-second ad shown three times). Then select another 25 for Treatment 3 and so on until you have assigned 125 of the 150 students to Treatments 1 through 5. The 25 students who remain get Treatment 6.
![]() The randomization is straightforward but very tedious to do by using
random digits. We strongly recommend that you use software, such as
Excel or the Simple Random Sample applet.
The randomization is straightforward but very tedious to do by using
random digits. We strongly recommend that you use software, such as
Excel or the Simple Random Sample applet.
Check-in
-
3.18 Do the randomization. Use computer software to carry out the randomization for Example 3.22. Show your work by including the random uniform numbers in your final spreadsheet.
Cautions about experimentation
The logic of a randomized comparative experiment depends on our ability to treat all the experimental units identically in every way except for the actual treatments being compared. Good experiments, therefore, require careful attention to details. The ideal situation is where a study is double-blind—neither the subjects themselves nor the experimenters know which treatment any subject has received. The double-blind method avoids unconscious bias by, for example, a doctor who doesn’t think that “just a placebo” can benefit a patient.
![]() Many—perhaps most—experiments have some weaknesses in detail. The
environment of an experiment can influence the outcomes in
unexpected ways.
Although experiments are the gold standard for evidence of cause and
effect,
really convincing evidence usually requires that a number of studies
in different places with different details produce similar results.
Here are some brief examples of what can go wrong.
Many—perhaps most—experiments have some weaknesses in detail. The
environment of an experiment can influence the outcomes in
unexpected ways.
Although experiments are the gold standard for evidence of cause and
effect,
really convincing evidence usually requires that a number of studies
in different places with different details produce similar results.
Here are some brief examples of what can go wrong.
Example 3.23 Placebo for a blueberry experiment.
A study of the effects of blueberries on bone health recruited healthy young women and men who were participating in a summer computing camp. Some were randomly assigned to eat 2 cups of blueberries per day for two weeks, and others were given green grapes as a placebo. The placebo did not work for this experiment: the two groups could see that they were receiving different treatments, and the measurements that were taken suggested that the experiment was related to bone health.
A serious potential weakness of experiments is lack of realism. The subjects or treatments or setting of an experiment may not realistically duplicate the conditions we really want to study. Here is an example.
Example 3.24 Layoffs and feeling bad.
How do layoffs at a workplace affect the workers who remain on the job? To try to answer this question, psychologists asked student subjects to proofread text for extra course credit and then “let go” some of the workers (who were actually accomplices of the experimenters). Some subjects were told that those let go had performed poorly (Treatment 1). Others were told that not all could be kept and that it was just luck that they were kept and others let go (Treatment 2). We can’t be sure that the reactions of the students are the same as those of workers who survive a layoff in which other workers lose their jobs. Many behavioral science experiments use student subjects in a campus setting. Do the conclusions apply to the real world?
Lack of realism can limit our ability to apply the conclusions of an
experiment to the settings of greatest interest. Most experimenters
want to generalize their conclusions to some setting wider than that
of the actual experiment.
![]() Statistical analysis of an experiment cannot tell us how far the
results will generalize to other settings. Nonetheless, the randomized comparative experiment, because of its
ability to give convincing evidence for causation, is one of the most
important ideas in statistics.
Statistical analysis of an experiment cannot tell us how far the
results will generalize to other settings. Nonetheless, the randomized comparative experiment, because of its
ability to give convincing evidence for causation, is one of the most
important ideas in statistics.
Matched pairs designs
Completely randomized designs are the simplest statistical designs for experiments. They illustrate clearly the principles of control, randomization, and repetition. However, completely randomized designs are often inferior to more elaborate statistical designs. In particular, matching the subjects in various ways can produce more precise results than simple randomization.
The simplest use of matching is a matched pairs design, which compares just two treatments. The subjects are matched in pairs. For example, an experiment to compare two advertisements for the same product might use pairs of subjects with the same age, sex, and income. The idea is that matched subjects are more similar than unmatched subjects so that comparing responses within a number of pairs is more efficient than comparing the responses of groups of randomly assigned subjects. Randomization remains important: which one of a matched pair sees the first ad is decided at random. One common variation of the matched pairs design imposes both treatments on the same subjects so that each subject serves as his or her own control. Here is an example.
Example 3.25 Matched pairs for the smartphone prototype experiment.
Example 3.18 describes an experiment to compare two prototypes of a new smartphone. The experiment compared two treatments: Phone 1 and Phone 2. The response variable is the satisfaction of the college student participant with the new smartphone. In Example 3.18, 40 student subjects were assigned at random, 20 students to each phone. This is a completely randomized design, outlined in Figure 3.3. Subjects differ in how satisfied they are with smartphones in general. The completely randomized design relies on chance to create two similar groups of subjects.
If we wanted to do a matched pairs version of this experiment, we would have each college student use each phone for two weeks. An effective design would randomize the order in which the phones are evaluated by each student. This would eliminate bias due to the possibility of the first phone evaluated being systematically evaluated higher or lower than the second phone evaluated.
The completely randomized design uses chance to decide which subjects will evaluate each smartphone prototype. The matched pairs design uses chance to decide which 20 subjects will evaluate Phone 1 first. The other 20 will evaluate Phone 2 first. This experiment is called a cross-over experiment. Situations where there are more than two treatments and all subjects receive all treatments can also be performed in this way.
Block designs
The matched pairs design of Example 3.25 uses the principles of comparison of treatments, randomization, and repetition on several experimental units. However, the randomization is not complete (all subjects randomly assigned to treatment groups) but is restricted to assigning the order of the treatments for each subject. Block designs extend the use of “similar subjects” from pairs to larger groups.
Block designs can have blocks of any size. A block design combines the idea of creating equivalent treatment groups by matching with the principle of forming treatment groups at random. Blocks are another form of control. They control the effects of some outside variables by bringing those variables into the experiment to form the blocks. Here are some typical examples of block designs.
Example 3.26 Blocking in a cancer experiment.
The progress of a type of cancer differs in women and men. A clinical experiment to compare three therapies for this cancer then treats sex as a blocking variable. Two separate randomizations are done, one assigning the female subjects to the treatments and the other assigning the male subjects. Figure 3.6 outlines the design of this experiment. Note that there is no randomization involved in making up the blocks. They are groups of subjects who differ in some way (sex in this case) that is apparent before the experiment begins.
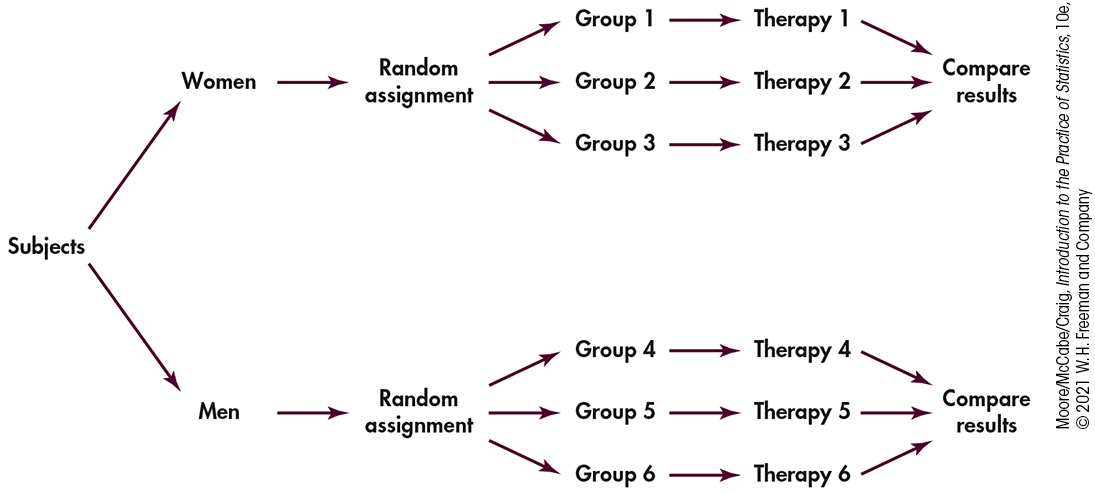
Figure 3.6 Outline of a block design, Example 3.26. The blocks consist of male and female subjects. The treatments are the three therapies for cancer.
Example 3.27 Blocking in an agriculture experiment.
The soil type and fertility of farmland differ by location. Because of this, a test of the effect of tillage type (two types) and pesticide application (three application schedules) on soybean yields uses small fields as blocks. Each block is divided into six plots, and the six treatments are randomly assigned to plots separately within each block.
Example 3.28 Blocking in an education experiment.
The Tennessee STAR class size experiment (Example 3.11, page 161) used a block design. It was important to compare different class types in the same school because the children in a school come from the same neighborhood, follow the same curriculum, and have the same school environment outside class. In all, 79 schools across Tennessee participated in the program. That is, there were 79 blocks. New kindergarten students were randomly placed in the three types of class separately within each school.
Blocks allow us to draw separate conclusions about each block—for example, about men and women in the cancer study in Example 3.26. Blocking also allows more precise overall conclusions because the systematic differences between men and women can be removed when we study the overall effects of the three therapies. The idea of blocking is an important additional principle of statistical design of experiments. A wise experimenter will form blocks based on the most important unavoidable sources of variability among the experimental units. Randomization will then average out the effects of the remaining variation and allow an unbiased comparison of the treatments.