9.1 Inference for Two-Way Tables
When we studied inference for two proportions in Section 8.2, we summarized the raw data by giving the number of observations from each population (n) and how many of them were classified as “successes” (X).
Example 9.1 Lost wallets.
![]()
In Example 8.11 (page 469), we compared the proportions of returned lost wallets with no money and with money. The following table summarizes the data used in that comparison:
| Wallet condition |
|
|
|
|---|---|---|---|
| Money | 300 | 174 | 0.58 |
| No money | 300 | 111 | 0.37 |
These data suggest that wallets with money are more likely to be
returned (58%) than are wallets with no money (37%). In
Example 8.12
(page 470), we
reported the difference between the proportions
In this chapter, we consider a different summary of the data. Rather than record just the count of returned wallets (X), we record counts of all the outcomes in a two-way table.
Example 9.2 Two-way table for lost wallets.
![]()
Here is the two-way table classifying the 600 wallets:
| Two-way table for lost wallets | |||
|---|---|---|---|
| Wallet condition | |||
| Returned | Money | No money | Total |
| No | 126 | 189 | 315 |
| Yes | 174 | 111 | 285 |
| Total | 300 | 300 | 600 |
We use the term
It is these
Here is another example of a
Example 9.3 Vaccinations and political party preference.
![]()

Should parents be able to decide whether or not to vaccinate their children, or should all vaccinations be required for all children? A Pew Internet survey asked this question of U.S. adults aged 18 and over.1 It also asked adults about their political preference. The following table breaks down the responses:
| Observed numbers of adults | |||
|---|---|---|---|
| Party | |||
| Required | Democratic | Republican | Total |
| No | 230 | 258 | 488 |
| Yes | 729 | 479 | 1208 |
| Total | 959 | 737 | 1696 |
The two categorical variables are Required, with values “No” and “Yes,” and Party, with values “Democrat” and “Republican.” We view Party as an explanatory variable and Required as a categorical response variable.
In Chapter 2, we discussed two-way tables and using the joint, marginal, and conditional distributions to study the relationship between the two categorical variables. We now view these sample distributions as estimates of the corresponding population distributions. Let’s look at some software output that gives these distributions.
Example 9.4 Software output for vaccinations and political party.
![]()
Figure 9.1 shows the output from JMP, Minitab, and SPSS for the vaccination data of Example 9.3. For now, we will just concentrate on the different distributions. Later, we will explore other parts of the output.
The three packages use similar displays for the distributions. In the
cells of the
Let’s look at the entries in the upper-left cell of the JMP output. We see that there are 230 Democrats (the count entry) who think vaccinations should not be required. The entry below the counts (Total %) tells us that these 230 represent 13.56% of the study participants. The four entries in the table for Total % give the joint distribution. The 230 Democrats who think that vaccinations should not be required represent 23.98% (Col %) of the Democrats in the study. This entry together with the (Col %) entry for the Democrat column in the Yes row (76.02%) gives the conditional distribution of Required for Democrats. The conditional distribution of Party given the opinion that vaccinations are not required are the Row % entries in the top two cells (47.13% and 52.87%). The marginal distributions are in the rightmost column and the bottom row. Minitab and SPSS give the same information but not necessarily in the same order.
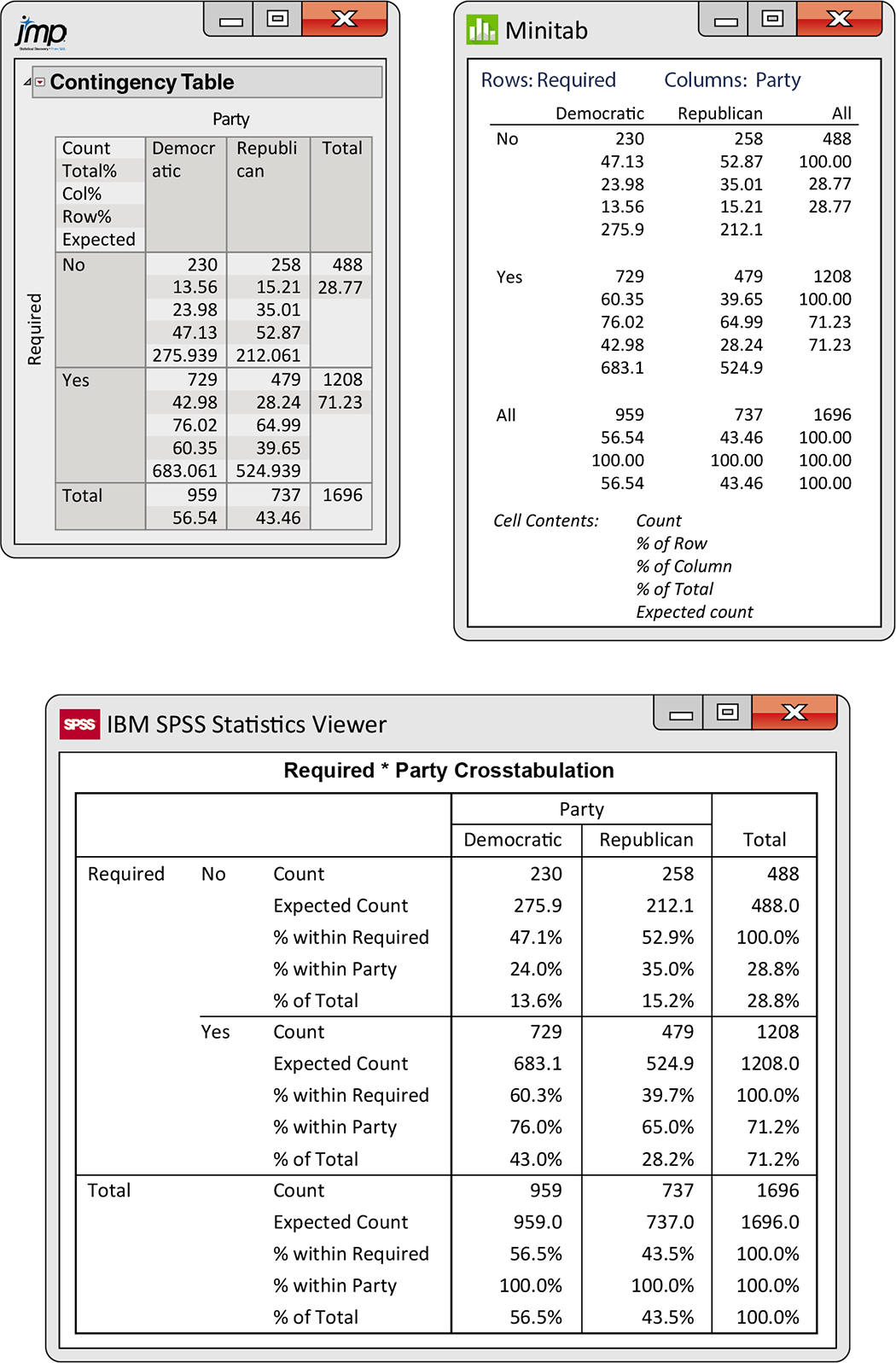
Figure 9.1 JMP, Minitab, and SPSS outputs, Examples 9.3 and 9.4.
In Chapter 2, we learned that the key to examining the relationship between two categorical variables is to look at the conditional distributions. Let’s do that for the vaccination data.
Example 9.5 Conditional distributions given political party.
![]()
To compare the frequency of vaccination opinions across political party preference, we examine the column percents. Here they are, rounded from the output in Figure 9.1 for clarity:
| Column percents for political party | ||
|---|---|---|
| Party | ||
| Required | Democratic | Republican |
| No | 24% | 35% |
| Yes | 76% | 65% |
| Total | 100% | 100% |
The “Total” row reminds us that 100% of the Democrats and Republicans have been classified as either thinking that vaccinations should be required or not. (The sums sometimes differ slightly from 100% because of roundoff error.) The bar graphs in Figure 9.2 compare the percents. The difference of 11% between the percents of adults who think vaccinations should not be required is reasonably large (24% for Democrats versus 35% for Republicans).
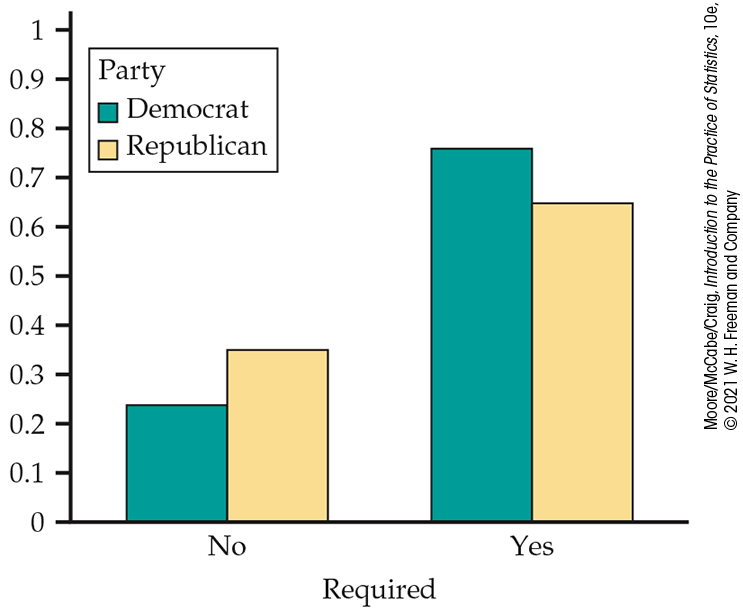
Figure 9.2 Bar graph of the percents of adults who believe vaccinations should not be required (no) and who believe that vaccinations should be required (yes), by political party preference, Example 9.5.
A statistical test will tell us whether or not this difference can be plausibly attributed to chance. Specifically, if there is no association between party preference and opinions about requiring vaccinations, how likely is it that a sample would show a difference as large as or larger than that displayed in Figure 9.2? In the next part of this section, we discuss the significance test to examine this question.
Note that Figure 9.2 shows the percents favoring required vaccinations (yes) as well as percents opposed (no). In a description of the results, we would choose one of these for our main story. For tables with more than two columns, we would normally plot the percents for all columns. The next example presents another way to display the data from a two-way table.
Example 9.6 Mosaic plot for vaccination opinions and political party preference.
![]()
Figure 9.3 displays the joint distribution and the two marginal distributions in a single plot, called a mosaic plot. It also shows the conditional distributions by party. The sizes of the four rectangles are proportional to the four probabilities of the joint distribution. The bar at the right side gives the marginal distribution of the Required variable, while the widths of the vertical bars give the marginal distribution of the variable Party. Within each of the two vertical bars, the blue and yellow sections make up the conditional distribution by party.
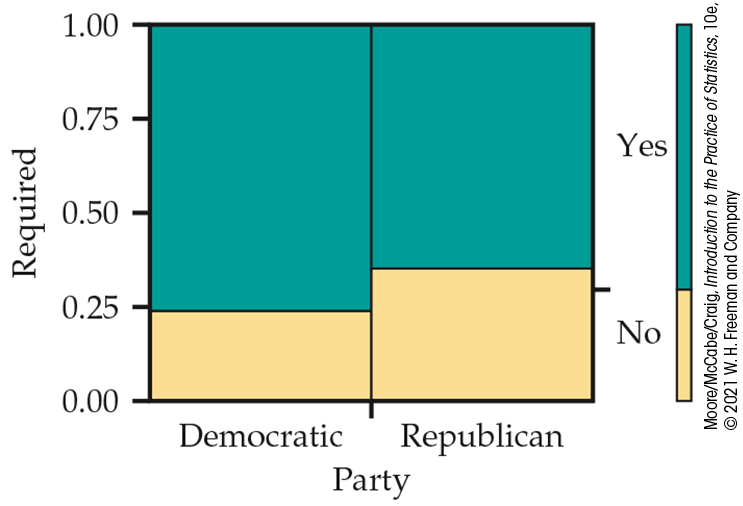
Figure 9.3 Mosaic plot for the vaccinations and political party data, Example 9.6.
Check-in
-
9.1 Find two conditional distributions for the lost wallet data. Figure 9.4 shows JMP output for the lost wallets data of Example 9.2 (page 487). Use this output to answer the following questions.
-
Find the conditional distribution of Returned for wallets with money.
Do the same for wallets with no money.
-
Graphically display the two conditional distributions.
-
Write a short summary interpreting the two conditional distributions.
-
-
9.2 Condition on wallet. Refer to the previous Check-in question. Use the output in Figure 9.4 to answer the following questions.
-
Find the conditional distribution of Condition for returned wallets.
Do the same for wallets that were not returned.
-
Graphically display the two conditional distributions.
-
Write a short summary interpreting the two conditional distributions.
-
-
9.3 Which conditional distributions should you use? Refer to your answers to the two previous Check-in questions. Which of these distributions do you prefer for interpreting these data? Give reasons for your answer.
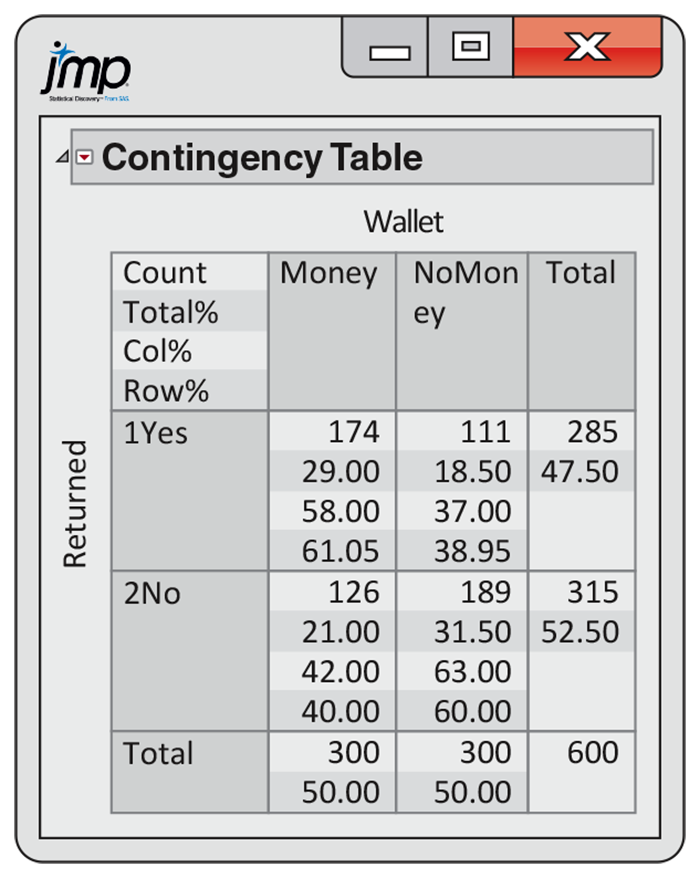
Figure 9.4 JMP output for lost wallets, Check-in questions 9.1, 9.2, and 9.3.
The hypothesis: No association
The null hypothesis
In our example, the hypothesis
For other two-way tables, such as the lost wallet study of Example 9.2, we have samples from two populations, one for each condition. For each population there is a distribution of the categorical response variable Returned. For two-way tables like this, the columns correspond to independent samples from c distinct populations, there are c distributions for the row variable, one for each population. The null hypothesis then says that the c distributions of the row variable are identical. The alternative hypothesis is that the distributions are not all the same.
Expected cell counts
To test the null hypothesis in
Example 9.7 Expected counts.
![]()
The observed and expected counts for the vaccination example appear in the JMP, Minitab, and SPSS computer outputs shown in Figure 9.1 (page 489). The expected counts are given as the last entry in each cell for JMP and Minitab and as the second entry in each cell for SPSS. For example, in the cell for Democrats who do not think that vaccinations should be required, the observed count is 230, and the expected count is 275.939 (JMP) or 275.9 (Minitab and SPSS).
How is this expected count obtained? Look at the percents in the right margin of the JMP table in Figure 9.1. We see that 28.77% of all adults thought that vaccinations should not be required. If the null hypothesis of no relation between Party and Required is true, we expect this overall percent to apply to both Democrats and Republicans. In particular, we expect 28.77% of the Democrats to be opposed to making vaccinations required. Because there are 959 Democrats, the expected count is 28.77% of 959, or 275.39. The other expected counts are calculated in the same way.
The reasoning of Example 9.7 leads to a simple formula for calculating expected cell counts. To compute the expected count of Democrats opposed to requiring vaccinations, we multiplied the proportion of adults opposed to requiring vaccinations (488/1696) by the number of Democrats (959). From Figure 9.1, we see that the numbers 488 and 959 are the row and column totals for the cell of interest and that 1696 is n, the total number of observations for the table. The expected cell count is, therefore, the product of the row and column totals divided by the table total.
The reasoning is similar for the wallet data in Example 9.2. Under the null hypothesis, the two populations defined by Condition have the same distribution. The common distribution is estimated by the marginal counts for Returned, 315 and 285. Expressed as percents, the distribution is 52.5% (315/600) for “No” and 47.5.5% (285/600) for “Yes.” The population “Money” has 300 samples, so the expected count is 52.5% of 300, or 157.5, for the cell defined by “Money” and “No.” Expected counts for the other three cells are calculated in the same way.
In Figure 9.3 (page 491), we used a mosaic plot to display the data for the vaccination and political party preference data. Looking at the two columns, we can see that the proportion in the lower region, corresponding to being opposed to required vaccinations, is smaller for the Democrats than for the Republicans. This illustrates graphically the difference in the conditional distributions for the two parties.
What would the mosaic plot look like if the null hypothesis were true? In this case, the two conditional distributions would be the same. Ideally, the observed counts would be equal to the expected counts. If we rerun the analysis with the expected counts in place of the observed counts, we obtain the mosaic plot in Figure 9.5. Notice that the proportions of each party responding no are now the same and equal to 28.77%, the marginal percent of adults who do not think vaccinations should be required.
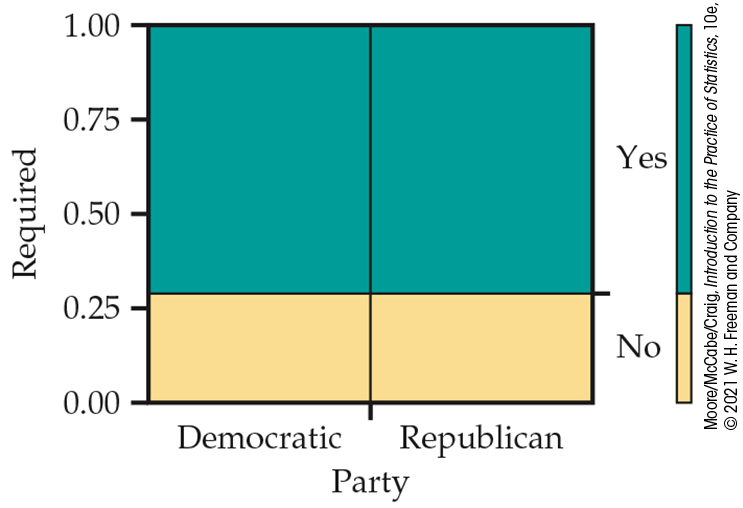
Figure 9.5 Mosaic plot for vaccinations and political party preference, assuming that the null hypothesis, no association, is true.
The chi-square test
![]()
To test
-
First, take the difference between each observed count and its
corresponding expected count. Verify that the sum of the
- Then, square these values so that they are all either 0 or positive.
- Because a large difference means less if it comes from a cell that is expected to have a large count, divide each squared difference by the expected count. This is a type of standardization.
- Finally, sum over all cells.
The result is called the chi-square statistic
If the expected counts and the observed counts are very different, a
large value of
Like the t distributions, the
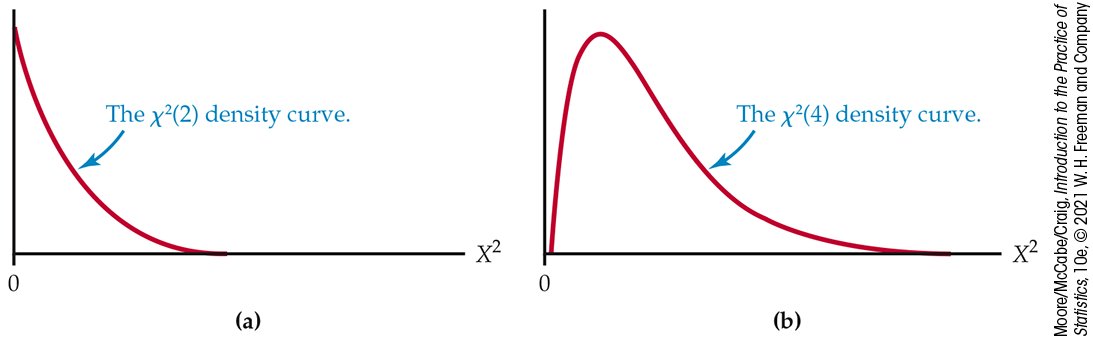
Figure 9.6 The
Now that we have our test statistic and its sampling distribution
under
The chi-square test always uses the upper tail of the
Example 9.8 Chi-square significance test.
![]()
The results of the chi-square significance test for the vaccination
example appear in the computer outputs in
Figure 9.7, labeled Pearson (JMP) or Pearson Chi-square (Minitab and SPSS).
Because all the expected cell counts are large (5 or more), the
As a check, we verify that the degrees of freedom are correct for a
The chi-square test confirms that the data provide evidence against
the null hypothesis that there is no relationship between political
party preference and vaccination opinion. Under
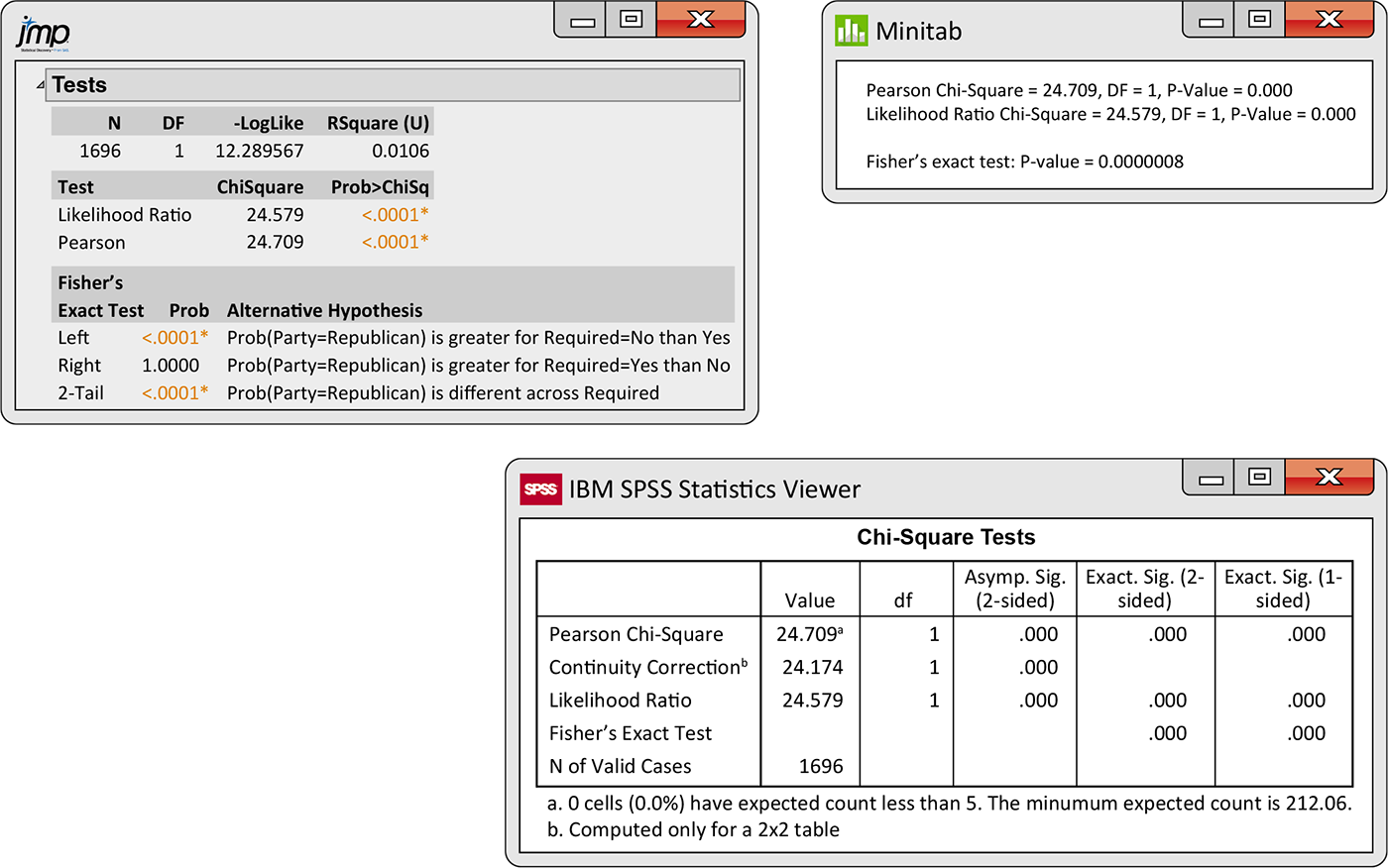
Figure 9.7 Significance test results from JMP, Minitab, and SPSS, Example 9.8.
The outputs in Figure 9.7 also report results for testing the hypothesis of no association using alternatives to the chi-square significance test. Fisher’s exact test is preferred by many, particularly when the counts are small and the chi-square approximation is not very accurate. Its results are provided in each of the software outputs.
The significance test result does not provide insight into the nature of the relationship between the variables. It is up to us to see that the data show Republicans are more likely to believe that vaccinations should not be required. You should always accompany a chi-square test by percents such as those in Example 9.5 and Figure 9.2 and by a description of the nature of the relationship.
Observational studies such as the one in Example 9.3 cannot tell us whether or not an explanatory variable is a cause of a pattern in a response variable. For the vaccine and party preference setting, a causal association does not seem plausible. Often, association can be explained by confounding with other variables. Similarly, the results for the wallet data in Exercise 9.2 tell us that wallets with money are treated differently, but they do not explain the underlying reason for this behavior.
Computations
The calculations required to analyze a two-way table are straightforward but tedious. In practice, we recommend using software, but it is possible to do the work with a calculator or a spreadsheet, and some insight can be gained by examining the details. Here is an outline of the steps required.
The next few examples illustrate these steps.
Example 9.9 Health habits of college students.
![]()

Physical activity generally declines when students leave high school and enroll in college. This suggests that college is an ideal setting to promote physical activity. One study examined the level of physical activity and other health-related behaviors in a sample of 1184 college students.2 Let’s look at the data for physical activity and consumption of fruits. The study categorized physical activity as low, moderate, or vigorous and fruit consumption as low, medium, or high. Here is the two-way table that summarizes the data:
| Physical activity | ||||
|---|---|---|---|---|
| Fruit consumption | Low | Moderate | Vigorous | Total |
| Low | 69 | 206 | 294 | 569 |
| Medium | 25 | 126 | 170 | 321 |
| High | 14 | 111 | 169 | 294 |
| Total | 108 | 443 | 633 | 1184 |
This table includes the marginal totals obtained by summing across
rows and columns. For example, the first-row total is
![]() It is easy to make an error in these calculations, so if doing this
by hand, it is a good idea to do both as a check on your
arithmetic.
It is easy to make an error in these calculations, so if doing this
by hand, it is a good idea to do both as a check on your
arithmetic.
Computing conditional distributions
First, we summarize the observed relation between physical activity and fruit consumption. We expect a positive association, but there is no clear distinction between an explanatory variable and a response variable in this setting. If we have such a distinction, then the clearest way to describe the relationship is to compare the conditional distributions of the response variable for each value of the explanatory variable. Otherwise, we can compute the conditional distribution each way and then decide which gives a better description of the data.
Example 9.10 Health habits of college students: Conditional distributions.
![]()
Let’s look at the data in the first column of the table in Example 9.9. There were 108 students with low physical activity. Of these, there were 69 with low fruit consumption. Therefore, the column proportion for this cell is
That is, 63.9% of the low physical activity students had low fruit consumption. Similarly, 25 of the low physical activity students had medium fruit consumption. This percent is 23.1%:
In all, we calculate nine percents. Here are the results:
| Column percents for fruit consumption and physical activity | ||||
|---|---|---|---|---|
| Physical activity | ||||
| Fruit consumption | Low | Moderate | Vigorous | Total |
| Low | 63.9 | 46.5 | 46.4 | 48.1 |
| Medium | 23.1 | 28.4 | 26.9 | 27.1 |
| High | 13.0 | 25.1 | 26.7 | 24.8 |
| Total | 100.0 | 100.0 | 100.0 | 100.0 |
In addition to the conditional distributions of fruit consumption for each level of physical activity, the table also gives the marginal distribution of fruit consumption. These percents appear in the rightmost column, labeled “Total.”
The sum of the percents in each column should be 100, except for
possible small roundoff errors.
![]() It is good practice to calculate each percent separately and then
sum each column as a check. In this way, we can find arithmetic errors that would not be
uncovered if, for example, we calculated the column percent for the
“High” row by subtracting the sum of the percents for “Low” and
“Medium” from 100.
It is good practice to calculate each percent separately and then
sum each column as a check. In this way, we can find arithmetic errors that would not be
uncovered if, for example, we calculated the column percent for the
“High” row by subtracting the sum of the percents for “Low” and
“Medium” from 100.
Figure 9.8 compares the distributions of fruit consumption for each of the three physical activity levels. For each activity level, the highest percent is for students who consume low amounts of fruit. For low physical activity, there is a clear decrease in the percent when moving from low to medium to high fruit consumption. The patterns for moderate physical activity and vigorous physical activity are similar. Low fruit consumption is still dominant, but the percents for medium and high fruit consumption are about the same for the moderate and vigorous activity levels. The percent of low fruit consumption is highest for the low physical activity students compared with those who have moderate or vigorous physical activity. These plots suggest that there is an association between these two variables.
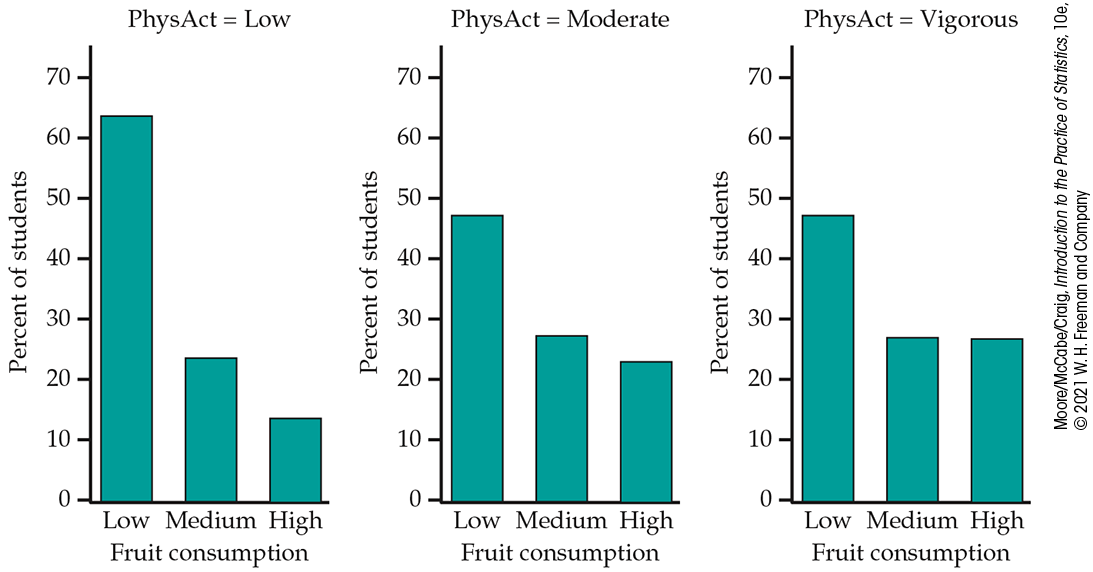
Figure 9.8 Comparison of the distribution of fruit consumption for different levels of physical activity, Example 9.10.
Check-in
-
9.4 Examine the row percents. Refer to the health habits data that we examined in Example 9.9 (page 496). For the row percents, make a table similar to the one in Example 9.10 (page 497).

-
9.5 Make some plots. Refer to the previous Check-in question. Make plots of the row percents similar to those in Figure 9.8.
-
9.6 Compare the conditional distributions. Compare the plots you made in the previous Check-in question with those given in Figure 9.8. Which set of plots do you think gives a better graphical summary of the relationship between these two categorical variables? Give reasons for your answer. Note that there is not a clear right or wrong answer for this exercise. You need to make a choice and to explain your reasons for making it.
We observe a clear relationship between physical activity and fruit consumption in this study. The chi-square test assesses whether this observed association is statistically significant—that is, too strong to occur often just by chance. The test confirms only that there is some relationship. The percents we have compared describe the nature of the relationship.
![]() The chi-square test does not in itself tell us what population our
conclusion describes. The subjects in this study were college students from four
midwestern universities. The researchers could argue that these
findings apply to college students in general. This type of inference
is important, but it is based on expert judgment and is beyond the
scope of the statistical inference that we have been studying.
The chi-square test does not in itself tell us what population our
conclusion describes. The subjects in this study were college students from four
midwestern universities. The researchers could argue that these
findings apply to college students in general. This type of inference
is important, but it is based on expert judgment and is beyond the
scope of the statistical inference that we have been studying.
Example 9.11 The chi-square significance test for health habits of college students.
![]()
The first step in performing the significance test is to calculate the expected cell counts. Let’s start with the cell for students with low fruit consumption and low physical activity. Using the formula on page 493, we need three quantities:
- The corresponding row total, 569, which is the number of students who have low fruit consumption;
- The corresponding column total, 108, which is the number of students who have low physical activity; and
- The total number of students, 1184.
The expected cell count is, therefore,
Note that although any observed count of the number of students must be a whole number, an expected count need not be.
Calculations for the other eight cells in the
When we add the terms for each of the nine cells, the result is
Because there are
Under the null hypothesis that fruit consumption and physical
activity are independent, the test statistic
|
|
||
| p | 0.01 | 0.005 |
|
|
13.28 | 14.86 |
The calculated value
=1-CHISQ.DIST(14.15,4,TRUE) gives the value as 0.0068.)
There is strong evidence
We can check our work by adding the expected counts to obtain the row and column totals, as in the table of Example 9.10 (page 497). These totals should be the same as those in the table of observed counts except for small roundoff errors.
Check-in
-
9.7 Find the expected counts. Refer to Example 9.11. Compute the expected counts and display them in a
-
9.8 Find the
-
9.9 Find the P-value. For each of the following, give the degrees of freedom and an appropriate bound on the P-value for the
-
-
9.10 Lost wallets: The chi-square test. Refer to Example 9.2 (page 487). Use the chi-square test to assess the relationship between money in a lost wallet and the chance that it is returned. State your conclusion.
The chi-square test and the z test
A comparison of the proportions of “successes” in two populations
leads to a
Example 9.12 Chi-square and z for political preference and vaccines.
![]()
In Example 9.8 we
performed the significance test to examine the relationship between
political preference and whether vaccinations should be required. We
calculated the text statistic
Check-in
-
9.11 Comparison of conditional distributions. Consider the following

Observed counts Response variable (Y) Explanatory variable (X) Total 1 2 Yes 72 96 168 No 138 114 252 Total 210 210 420 -
Compute the conditional distribution of the response variable for each of the two explanatory-variable categories.
Display the distributions graphically.
-
Write a short paragraph describing the two distributions and how they differ.
-
-
9.12 Expected cell counts and the chi-square test. Refer to the previous Check-in question. You consider using the chi-square test to compare these two conditional distributions.
-
Find the expected counts for all cells. Are they large enough to justify use of the chi-square test for these data?
-
Computer software gives you
-
Using Table F, give an appropriate bound on the P-value.
-
-
9.13 Compare the chi-square test with the z test. Refer to the previous two Check-in questions and the significance test for comparing two proportions (page 474).
-
Set up the problem as a comparison between two proportions. Describe the population proportions, state the null and alternative hypotheses, and give the sample proportions.
-
Carry out the significance test to compare the two proportions. Report the z statistic, the P-value, and your conclusion.
-
Compare the P-value for this significance test with the one that you reported in Check-in question 9.12.
-
Verify that the square of the z statistic is the
-
Example 9.13 Meta-analysis for eating too much salt.

Evidence from a variety of sources suggests that diets high in salt are associated with risks to human health. To investigate the relationship between salt intake and stroke, information from 14 studies was combined in a meta-analysis.3 Subjects were classified based on the amount of salt in their normal diet. They were followed for several years and then classified according to whether or not they had developed cardiovascular disease (CVD). A total of 104,933 subjects were studied, and 5161 of them developed CVD. Here are the data from one of the studies:4
| Low salt | High salt | |
|---|---|---|
| CVD | 88 | 112 |
| No CVD | 1081 | 1134 |
| Total | 1169 | 1246 |
Let’s look at the relative risk for this study. We first find the proportion of subjects who developed CVD in each group. For the subjects with a low salt intake, the proportion who developed CVD is
or 75 per thousand; for the high-salt group, the proportion is
or 90 per thousand. We can now compute the relative risk as the ratio of these two proportions. We choose to put the high-salt group in the numerator. The relative risk is
Relative risk greater than 1 means that the high-salt group developed more CVD than the low-salt group. For this study, the association is not statistically significant. The 95% confidence interval for the relative risk is (0.91, 1.56).
When the data from all 14 studies were combined, the relative risk
was reported as 1.17, with a 95% confidence interval of (1.02,
1.32). Because this interval does not include the value 1,
corresponding to equal proportions in the two groups, we conclude
that the higher CVD rates are not the same for the two diets
Check-in
-
9.14 A different view of the relative risk. In the previous example, we computed the relative risk for the high-salt group relative to the low-salt group. Now, compute the relative risk for the low-salt group relative to the high-salt group by inverting the relative risk reported in the meta-analysis in Example 9.13—that is, compute 1/1.17. Then restate the last paragraph of the exercise with this change. (Hint: For the lower confidence limit, use 1 divided by the upper limit for the original ratio and do a similar calculation for the upper limit.)
Section 9.1 SUMMARY
-
The null hypothesis for
-
Expected cell counts under the null hypothesis are computed using the formula
-
The null hypothesis is tested by the chi-square statistic, which compares the observed counts with the expected counts:
-
Under the null hypothesis,
-
where
-
The chi-square approximation is adequate for practical use when the average expected cell count is 5 or greater and all individual expected counts are 1 or greater, except in the case of
-
For two-way tables we first compute percents or proportions that describe the relationship of interest. Then, we compute expected counts, the
-
Two different models for generating
Section 9.1 EXERCISES
-
9.1 Eight is enough. A healthy body needs good food, and healthy teeth are needed to chew our food so that it can nourish our bodies. The U.S. Army has recognized this fact and requires recruits to pass a dental examination. If you wanted to be a soldier in the Spanish American War, which took place in 1898, you needed to have at least eight teeth. Here is the statement of the requirement:

Unless an applicant has at least four sound double teeth, one above and one below on each side of the mouth, and so opposed as to serve the purpose of mastication, he should be rejected.
A study reported the rejection data for enlistment candidates classified by age. Here are the data:5
Age Rejected <20 20–25 25–30 30–35 35–40 >40 Yes 68 647 1,114 1,783 2,887 3,801 No 58,884 77,992 55,597 43,994 47,569 39,985 -
Which variable is the explanatory variable? Which variable is the response variable? Give reasons for your answer.
-
Find the joint distribution. Write a brief summary explaining the major features of this distribution.
-
Find the two marginal distributions. Write a brief summary explaining the major features of these distributions.
-
Find conditional distributions and give a brief summary explaining the major features of these distributions.
-
-
9.2 Physical education requirements. In Exercise 8.41 (page 482), you analyzed data from a study that included 354 higher education institutions: 225 private and 129 public. Among the private institutions, 60 required a physical education course, while among the public institutions, 101 required a course. Your analysis in that exercise focused on the comparison of two proportions. Use these data to construct a two-way table for analysis and find the joint distribution, the marginal distributions, and the conditional distributions. Use these distributions to give a brief summary of the relationship between the type of institution and whether a physical education course is required.
-
9.3 Conditional distribution for eight is enough. Refer to Exercise 9.1. Which conditional distribution would you choose to explain the relationship between the two variables? Write a summary that includes your interpretation of the relationship based on this conditional distribution.
-
9.4 Conditional distribution for physical education requirements. Refer to Exercise 9.2. Which conditional distribution do you prefer to explain the results of your analysis? Give a reason for your answer.
-
9.5 Expected counts for eight is enough. Refer to Exercise 9.1. Find the expected counts.
-
9.6 Expected counts for physical education requirements. Refer to Exercise 9.2. Find the expected counts.
-
9.7 Significance test for eight is enough. Refer to Exercise 9.1. Find the chi-square statistic, the degrees of freedom, and the P-value. What do you conclude?
-
9.8 Significance test for physical education requirements. Refer to Exercise 9.2. Find the chi-square statistic, the degrees of freedom, and the P-value. What do you conclude?
-
9.9 Two views of the significance test for physical education requirements. Refer to Exercise 9.2. Show that the chi-square statistic that you found in Exercise 9.8 is the square of the z statistic that you found in Exercise 8.41 (page 482).
-
 9.10 Survival and class on the Titanic.
On April 15, 1912, on her maiden voyage, the
Titanic collided with an iceberg and sank. The ship was
luxurious but did not have enough lifeboats for the 2224
passengers and crew. As a result of the collision, 1502 people
died.6
The ship had three classes of passengers. The level of luxury
and the price of the ticket varied with the class, first class
being the most luxurious. There were 323 passengers in first
class, 277 in second class, and 709 in third class. The number
of first-class passengers who survived was 200. For second- and
third-class, the numbers were 119 and 181, respectively. Let’s
look at these data with a two-way table.
9.10 Survival and class on the Titanic.
On April 15, 1912, on her maiden voyage, the
Titanic collided with an iceberg and sank. The ship was
luxurious but did not have enough lifeboats for the 2224
passengers and crew. As a result of the collision, 1502 people
died.6
The ship had three classes of passengers. The level of luxury
and the price of the ticket varied with the class, first class
being the most luxurious. There were 323 passengers in first
class, 277 in second class, and 709 in third class. The number
of first-class passengers who survived was 200. For second- and
third-class, the numbers were 119 and 181, respectively. Let’s
look at these data with a two-way table.

-
Create a two-way table that you could use to explore the relationship between survival and class.
-
Which variable is the explanatory variable, and which is the response variable? Give reasons for your answers.
-
Find the two marginal distributions. Write a brief summary explaining the major features of these distributions.
-
Find the conditional distributions. Which conditional distribution would you choose to explain the relationship between these two variables? Explain your answer.
-
Find the expected counts, the
-
Write a summary of your analyses that includes your interpretation of the results.
-
-
9.11 Sexual harassment in middle and high schools.
A nationally representative survey of students in grades 7 to 12
asked about the experience of these students with respect to
sexual harassment.7
One question asked how many times the student had witnessed
sexual harassment in school. The two-way table for this exercise
is given in
Figure 9.9. Use the figure to find the joint distribution, the two
marginal distributions, and the conditional distributions. Which
conditional distribution do you prefer to explain the results of
your analysis? Give a reason for your answer.


Figure 9.9 JMP output, Exercises 9.11 and 9.13.
-
9.12 What’s wrong? Each of the following statements contains an error. Describe each error and explain why the statement is wrong.
-
A chi-square statistic is used to test the null hypothesis that two categorical variables are dependent.
-
Marginal distributions can be used to explain the relationship between variables in a two-way table.
-
A chi-square statistic is always the square of a z-statistic for comparing two proportions.
-
-
9.13 Sexual harassment in middle and high schools. Refer to Exercise 9.11. Use the output in Figure 9.9 to find the chi-square statistic, the degrees of freedom, and the P value. What do you conclude from this analysis?