6.4 Inference as a Decision
We have presented tests of significance as methods for assessing the
strength of evidence against the null hypothesis. This assessment is
made by the P-value, which is a probability computed under the
assumption that
There is, however, another way to think about these issues. Sometimes, we are really concerned about making a decision or choosing an action based on our evaluation of the data. Acceptance sampling is one such circumstance. Suppose a producer of ball bearings and a skateboard manufacturer agree that each shipment of bearings shall meet certain quality standards. When a lot of bearings arrives, the manufacturer chooses a sample of bearings to be inspected. On the basis of the sample outcome, the manufacturer will either accept or reject the lot. Let’s examine how the idea of inference as a decision changes the reasoning used in tests of significance.
Two types of error
Tests of significance concentrate on
on the basis of a sample of bearings.
We hope that our decision will be correct, but sometimes it will be wrong. There are two types of incorrect decisions. We can accept a bad lot of bearings, or we can reject a good lot. Accepting a bad lot injures the consumer, while rejecting a good lot hurts the producer. To help distinguish these two types of error, we give them specific names.
These possibilities are summarized in
Figure 6.16
for the acceptance sampling example. If
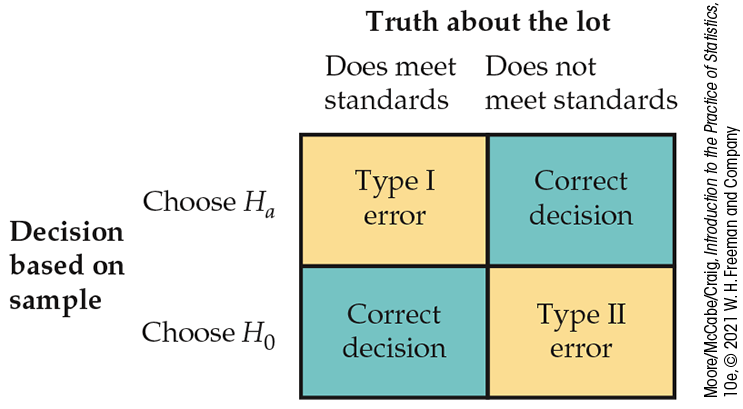
Figure 6.16 The two types of error in the acceptance sampling example.
Significance tests with fixed-level
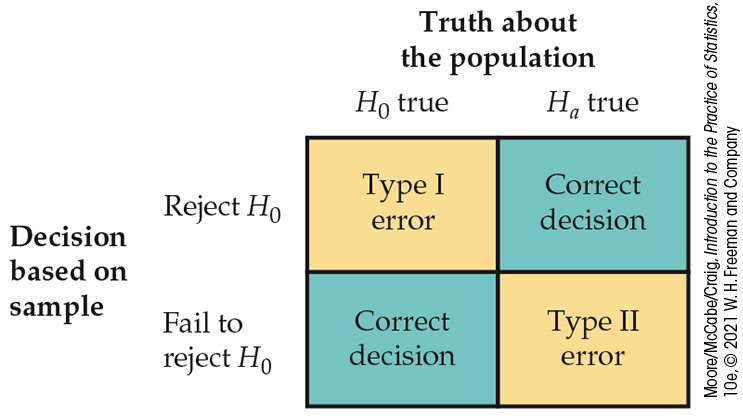
Figure 6.17 The two types of error as they relate to significance testing.
Error probabilities
Any rule for making decisions is assessed in terms of the probabilities of the two types of error. This is in keeping with the idea that statistical inference is based on probability. We cannot (short of inspecting the whole lot) guarantee that good lots of bearings will never be rejected and bad lots will never be accepted. But by random sampling and the laws of probability, we can say what the probabilities of both kinds of error are.
Example 6.29 Outer diameter of a skateboard bearing.

The mean outer diameter of a skateboard bearing is supposed to be
22.000 millimeters (mm). The outer diameters vary Normally, with
standard deviation
This is a test of the hypotheses
To carry out the test, the manufacturer computes the z statistic:
and rejects
A Type I error is to reject
What about Type II errors? Because there are many values of
Figure 6.18
shows how the two probabilities of error are obtained from the two
sampling distributions of
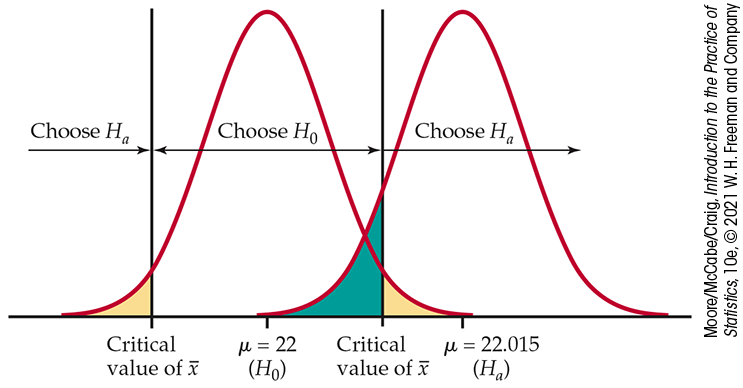
Figure 6.18 The two
error probabilities,
Example 6.29. The probability of a Type I error (yellow area) is the
probability of choosing
The probability of a Type I error is the probability of rejecting
The probability of a Type II error for the particular alternative
High power is desirable as it implies that the probability of a Type II error is small. Similar to choosing the sample size for a desired margin of error of a confidence interval (page 340), one can determine the sample size needed for a desired power at a particular alternative. We discuss the use of software to do these calculations in the next chapter.
For now, we can see from
Figure 6.18 that
the probability of a Type II error requires specifying the rejection
region in terms of
![]() The Statistical Power applet can also be used to compute the
error probabilities. For this calculation, we’d enter the null
The Statistical Power applet can also be used to compute the
error probabilities. For this calculation, we’d enter the null
The distinction between tests of significance and tests as rules for
deciding between two hypotheses does not lie in the calculations
but in the reasoning that motivates the calculations. In a test
of significance, we focus on a single hypothesis
If the same inference problem is thought of as a decision problem, we focus on two hypotheses and give a rule for deciding between them based on the sample evidence. Therefore, we must focus equally on two probabilities, the probabilities of the two types of error. We must choose one hypothesis and cannot abstain on grounds of insufficient evidence.
The common practice of testing hypotheses
Clearly distinguishing the two ways of thinking is helpful for
understanding. In practice, the two approaches often merge. We
continued to call one of the hypotheses in a decision problem
-
State
- Think of the problem as a decision problem, so that the probabilities of Type I and Type II errors are relevant.
-
Because of Step 1, Type I errors are more serious. So choose an
- Among these tests, select one that makes the probability of a Type II error as small as possible (that is, power as large as possible).
Testing hypotheses may seem to be a hybrid approach. It was,
historically, the effective beginning of decision-oriented ideas in
statistics. An impressive mathematical theory of hypothesis testing
was developed between 1928 and 1938 by Jerzy Neyman and Egon Pearson.
The decision-making approach came later (1940s). Because decision
theory in its pure form leaves you with two error probabilities and no
simple rule on how to balance them, it has been used less often than
either tests of significance or tests of hypotheses. Decision ideas
have been applied in testing problems mainly by way of the
Neyman–Pearson hypothesis-testing theory. That theory asks you first
to choose
Section 6.4 SUMMARY
-
An alternative to significance testing regards
-
In the case of testing
-
The power of a test measures its ability to detect an alternative hypothesis. The power to detect a specific alternative is calculated as the probability that the test will choose
-
In a fixed-level
Section 6.4 EXERCISES
-
6.78 A role as a statistical consultant. You are the statistical expert for a graduate student planning her PhD research. After you carefully present the mechanics of significance testing, she suggests using
-
6.79 What are the Type I and Type II errors? A smartphone manufacturer gets its phone batteries from one supplier. For each shipment, a random sample of
-
Specify the hypotheses the manufacturer must decide between.
-
Describe what a Type I and a Type II error would be, based on your specification of hypotheses in part (a).
-
-
 6.80 Choose the appropriate distribution. You
must decide which of two discrete distributions a random
variable X has. We will call the distributions
6.80 Choose the appropriate distribution. You
must decide which of two discrete distributions a random
variable X has. We will call the distributions
x 0 1 2 3 4 5 6 0.0 0.1 0.1 0.1 0.4 0.2 0.1 0.2 0.4 0.2 0.1 0.1 0.0 0.0 You have a single observation on X and wish to choose between
One possible decision procedure is to reject
-
Find the probability of a Type I error—that is, the probability that you choose
Find the probability of a Type II error.
-
-
6.81 Percent energy from added sugars: Type I and Type II errors. A test of significance was performed in Example 6.15 (page 357).
-
Describe the Type I and Type II errors in this example.
-
Based on the conclusion, which type of error might have occurred? Explain your answer.
-
-
6.82 Choose the appropriate distribution, continued.
Refer to
Exercise 6.80. Another possible decision procedure is to reject
-
Find the probabilities of a Type I and Type II error under this decision procedure.
-
Which decision procedure,
-
-
6.83 What is the power of the test? A study is run to test
-
The probability of a Type II error when
-
The probability of a Type II error when
-
The probability of a Type II error when
-
-
6.84 Computing the power in the ball bearing study. Recall Example 6.29. Let’s run through the steps needed to obtain the power of 0.92 when
-
Given that we reject
for what values of
-
Now assuming
-
-
 6.85 Power for a different alternative.
For the ball bearing example (page 376), the power is 0.92 when
6.85 Power for a different alternative.
For the ball bearing example (page 376), the power is 0.92 when
-
Would the power for the alternative
-
Use the Statistical Power applet to verify your answer in part (a).
-
-
6.86 More on choosing the appropriate distribution.
Refer to
Exercise 6.80. Suppose that instead of a single observation X, you
plan to obtain n observations and use the decision rule
to reject
-
What are the means of
-
Based on your answers in part (a), what would be a good choice for k? Explain your answer.
-
-
6.87 Computer-assisted career guidance systems. A wide variety of computer-assisted career guidance systems have been developed over the past decade. These programs use factors such as student interests, aptitude, skills, personality, and family history to recommend a career path. For simplicity, suppose that a program recommends that a high school graduate either go to college or join the workforce.
-
What are the two hypotheses and the two types of error that the program can make?
-
The program can be adjusted to decrease one error probability at the cost of an increase in the other error probability. Which error probability would you choose to make smaller, and why? (This is a matter of judgment. There is no single correct answer.)
-
-
6.88 Effect of changing the alternative μ on
power.
The Statistical Power applet can be used to study power.
Open the applet and set the null hypothesis to
-
6.89 Other changes and the effect on power.
Refer to the previous exercise. For each of the following
changes, explain what happens to the power for each alternative
Change to the two-sided alternative.
-
Decrease
-
Increase n from 10 to 30.
-
6.90 Make a recommendation. Your manager has asked you to review a research proposal that includes a section on sample size justification. A careful reading of this section indicates that the power is 18% for detecting an effect that would be considered important. Write a short report for your manager explaining what this means and make a recommendation on whether or not this study should be run as designed.