Chapter 2 EXERCISES
-
2.122 Dwelling permits and sales for 19 countries. The Organisation for Economic Co-operation and Development collects data on main economic indicators (MEIs) for many countries. Each variable is recorded as an index, with the year 2010 serving as a base year. This means that the variable for each year is reported as a ratio of the value for the year divided by the value for 2000. Use of indexes in this way makes it easier to compare values for different countries. Table 2.3 gives the values of three MEIs for 19 countries.33

-
Make a scatterplot with sales as the response variable and permits issued for new dwellings as the explanatory variable. Describe the relationship. Are there any outliers or influential observations?
-
Find the least-squares regression line and add it to your plot.
-
Interpret the slope of the line in the context of this exercise.
-
Interpret the intercept of the line in the context of this exercise. Explain whether or not this interpretation is useful in explaining the relationship between these two variables.
-
What is the predicted value of sales for a country that has an index of 117.8 for dwelling permits?
-
Canada has an index of 117.8 for dwelling permits. Find the residual for this country.
-
What percent of the variation in sales is explained by dwelling permits?
Table 2.3 Dwelling permits, sales, and production for 19 countries
Country Sales Production Dwelling permits Australia 107.2 107.1 88.8 Belgium 98.9 108.5 134.8 Canada 110.9 109.7 117.8 Chile 108.3 101.8 84.2 Czech Republic 116.5 113.5 127.1 Estonia 107.0 111.9 125.1 Finland 106.5 111.4 133.4 France 109.8 103.0 114.2 Germany 107.4 105.7 115.6 Greece 102.1 108.8 175.9 Hungary 118.1 109.8 302.4 Israel 117.6 104.0 95.0 Korea 110.5 106.1 67.0 Luxembourg 35.3 102.6 120.0 Netherlands 107.6 103.1 133.7 Norway 100.9 96.7 117.8 Poland 119.4 116.1 136.1 Slovenia 125.1 120.9 115.5 Spain 105.5 105.4 191.8 -
-
2.123 Dwelling permits and production. Refer to the previous exercise.
-
Make a scatterplot with production as the response variable and permits issued for new dwellings as the explanatory variable. Describe the relationship. Are there any outliers or influential observations?
-
Find the least-squares regression line and add it to your plot.
-
Interpret the slope of the line in the context of this exercise.
-
Interpret the intercept of the line in the context of this exercise. Explain whether or not this interpretation is useful in explaining the relationship between these two variables.
-
What is the predicted value of production for a country that has an index of 117.8 for dwelling permits?
-
Canada has an index of 117.8 for dwelling permits. Find the residual for this country.
-
What percent of the variation in production is explained by dwelling permits? How does this value compare with the value that you found in the previous exercise for the percent of variation in sales that is explained by building permits?
-
-
2.124 Sales and production. Refer to the previous two exercises.
-
Make a scatterplot with sales as the response variable and production as the explanatory variable. Describe the relationship. Are there any outliers or influential observations?
-
Find the least-squares regression line and add it to your plot.
-
Interpret the slope of the line in the context of this exercise.
-
Interpret the intercept of the line in the context of this exercise. Explain whether or not this interpretation is useful in explaining the relationship between these two variables.
-
What is the predicted value of sales for a country that has an index of 108.8 for production?
-
Greece has an index of 108.8 for production. Find the residual for this country.
-
What percent of the variation in sales is explained by production? How does this value compare with the percents of variation that you calculated in the two previous exercises?
-
-
2.125 Population in Canadian provinces and territories. Statistics Canada provides a great deal of demographic data organized in different ways.34 Figure 2.35 gives the percent of the population aged over 65 and the percent aged under 5 for each of the 13 Canadian provinces and territories. Figure 2.36 is a scatterplot of the percent of the population over 65 versus the percent under 5.

-
Write a short paragraph explaining what the plot tells you about these two demographic groups in the 13 Canadian provinces and territories.
-
Find the correlation between the percent of the population over 65 and the percent under 5. Does the correlation give a good numerical summary of the strength of this relationship? Explain your answer.
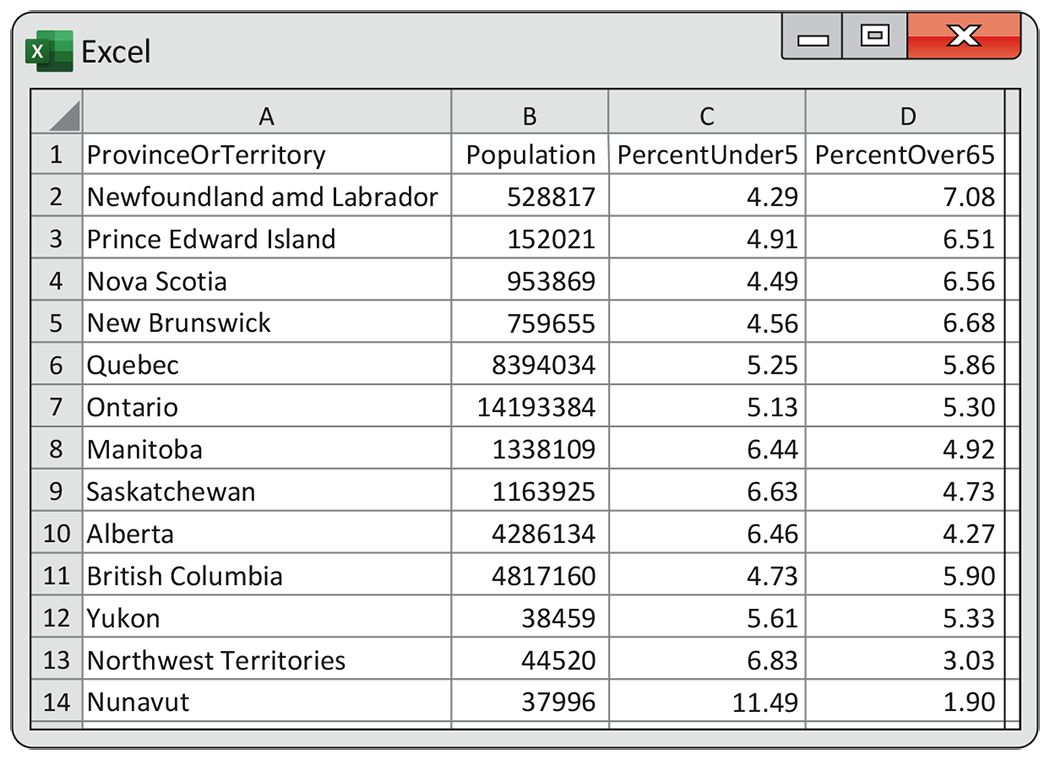
Figure 2.35 Percent of the population over 65 years and percent of the population under 5 years in the 13 Canadian provinces and territories, Exercise 2.125.
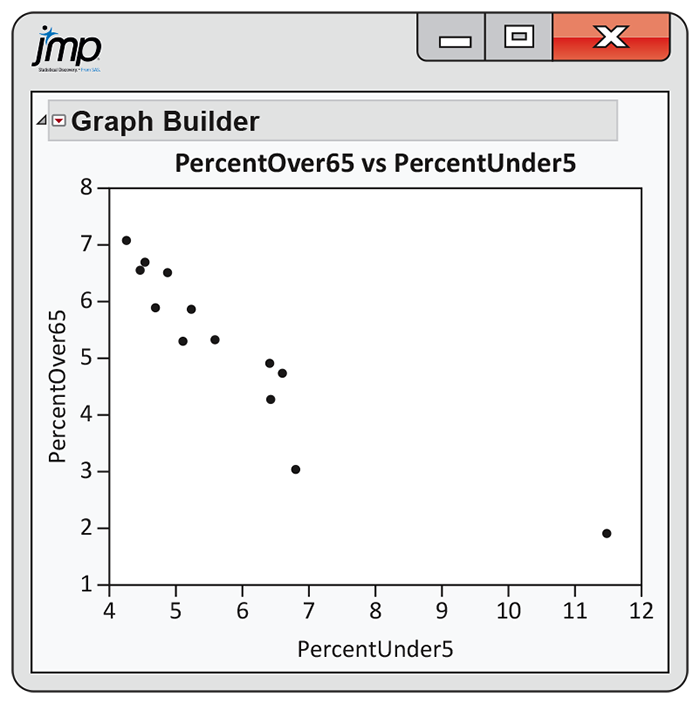
Figure 2.36 Scatterplot of percent of the population over 65 years versus percent of the population under 5 years for the 13 Canadian provinces and territories, Exercise 2.125.
-
-
2.126 Nunavut. Refer to the previous exercise and Figures 2.35 and 2.36.
Do you think that Nunavut is an outlier?
-
Make a residual plot for these data. Comment on the size of the residual for Nunavut. Use this information to expand on your answer to part (a).
-
Find the value of the correlation without Nunavut. How does this compare with the value you computed in part (b) of the previous exercise?
-
Write a short paragraph about Nunavut based on what you have found in this exercise and the previous one.
-
2.127 Compare the provinces with the territories. Refer to the previous exercise. The three Canadian territories are the Northwest Territories, Nunavut, and the Yukon Territories. All the other entries in Figure 2.35 are provinces.
-
Generate a scatterplot of the Canadian demographic data similar to Figure 2.36 but with the points labeled “P” for provinces and “T” for territories.
-
Use your new scatterplot to write a new summary of the demographics for the 13 Canadian provinces and territories.
-
-
2.128 Records for men and women in the 10K. Table 2.4 shows the progress of world record times (in seconds) for the 10,000-meter run for both men and women.35

-
Make a scatterplot of world record time against year, using separate symbols for men and women. Describe the pattern for each sex. Then compare the progress of men and women.
-
Women began running this long distance later than men, so we might expect their improvement to be more rapid. Moreover, it is often said that men have little advantage over women in distance running, as opposed to in sprints, where muscular strength plays a greater role. Do the data appear to support these claims?
Table 2.4 World record times for the 10,000-meter run
Men Women Record year Time (seconds) Record year Time (seconds) Record year Time (seconds) 1912 1880.8 1963 1695.6 1967 2286.4 1921 1840.2 1965 1659.3 1970 2130.5 1924 1835.4 1972 1658.4 1975 2100.4 1924 1823.2 1973 1650.8 1975 2041.4 1924 1806.2 1977 1650.5 1977 1995.1 1937 1805.6 1978 1642.4 1979 1972.5 1938 1802.0 1984 1633.8 1981 1950.8 1939 1792.6 1989 1628.2 1981 1937.2 1944 1775.4 1993 1627.9 1982 1895.3 1949 1768.2 1993 1618.4 1983 1895.0 1949 1767.2 1994 1612.2 1983 1887.6 1949 1761.2 1995 1603.5 1984 1873.8 1950 1742.6 1996 1598.1 1985 1859.4 1953 1741.6 1997 1591.3 1986 1813.7 1954 1734.2 1997 1587.8 1993 1771.8 1956 1722.8 1998 1582.7 2016 1757.5 1956 1710.4 2004 1580.3 1960 1698.8 2005 1577.5 1962 1698.2 -
-
2.129 Fields of study for college students. The table below gives the number of students (in thousands) graduating from college with degrees in several fields of study for seven countries:36
-
Calculate the marginal totals and add them to the table.
-
Find the marginal distribution of country and give a graphical display of the distribution.
-
Repeat part (b) for the marginal distribution of field of study.
Field of study Canada France Germany Italy Japan U.K. U.S. Social sciences, business, law 64 153 66 125 250 152 878 Science, mathematics, engineering 35 111 66 80 136 128 355 Arts and humanities 27 74 33 42 123 105 397 Education 20 45 18 16 39 14 167 Other 30 289 35 58 97 76 272 -
-
2.130 Fields of study by country for college students. In the previous exercise you examined data on fields of study for graduating college students from seven countries.
-
Find the seven conditional distributions of graduates in the different fields of study for each country.
Display the conditional distributions graphically.
-
Write a paragraph summarizing the relationship between field of study and country.
-
-
2.131 Graduation rates. One of the factors used to evaluate undergraduate programs is the proportion of incoming students who graduate. This quantity, called the graduation rate, can be predicted by other variables such as the SAT or ACT scores and the high school records of the incoming students. One of the components that U.S. News & World Report uses when evaluating colleges is the difference between the actual graduation rate and the rate predicted by a regression equation.37 In this chapter, we call this quantity the residual. Explain why the residual is a better measure to evaluate college graduation rates than the raw graduation rate.
-
2.132 Salaries and raises. For this exercise, we consider a hypothetical employee who starts working in Year 1 with a salary of $50,000. Each year her salary increases by approximately 5%. By Year 20, she is earning $126,000. The following table gives her salary for each year (in thousands of dollars):

Year Salary Year Salary Year Salary Year Salary 1 50 6 63 11 81 16 104 2 53 7 67 12 85 17 109 3 56 8 70 13 90 18 114 4 58 9 74 14 93 19 120 5 61 10 78 15 99 20 126 -
Figure 2.37 is a scatterplot of salary versus year, with the least-squares regression line. Describe the relationship between salary and year for this person.
-
The value of
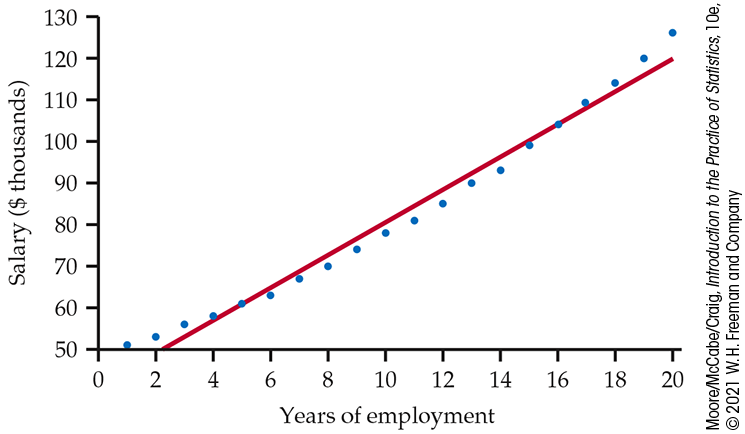
Figure 2.37 Plot of salary versus year for an individual who receives approximately a 5% raise each year for 20 years, with the least-squares regression line, Exercise 2.132.
-
-
2.133 Look at the residuals. Refer to the previous exercise. Figure 2.38 is a plot of the residuals versus year.
Interpret the residual plot.
-
Explain how this plot highlights the deviations from the least-squares regression line that you can see in Figure 2.37.
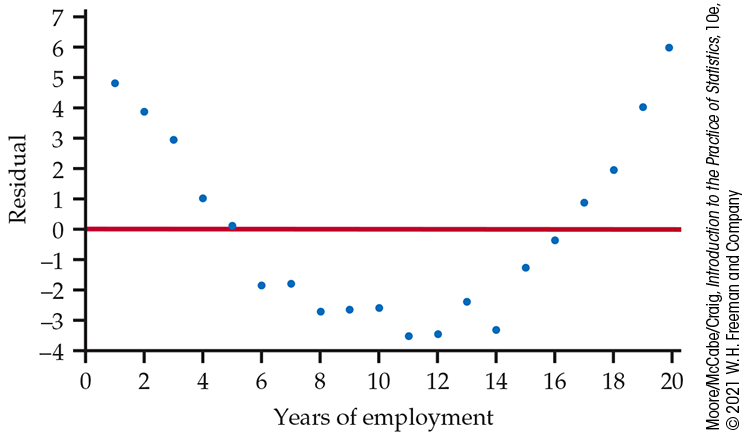
Figure 2.38 Plot of residuals versus year for an individual who receives approximately a 5% raise each year for 20 years, Exercise 2.133.
-
2.134 Try logs. Refer to the previous two exercises. Figure 2.39 is a scatterplot with the least-squares regression line for log salary versus year. For this model,
-
Compare this plot with Figure 2.37. Write a short summary of the similarities and the differences.
-
Figure 2.40 is a plot of the residuals for the model using year to predict log salary. Compare this plot with Figure 2.37 and summarize your findings.
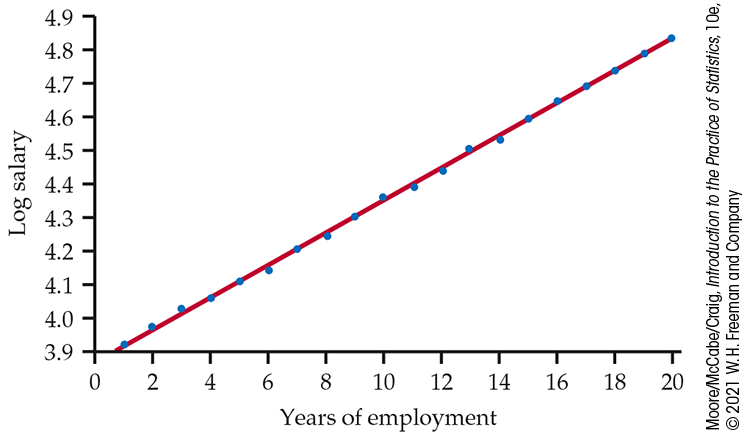
Figure 2.39 Plot of log salary versus year for an individual who receives approximately a 5% raise each year for 20 years, with the least-squares regression line, Exercise 2.134.
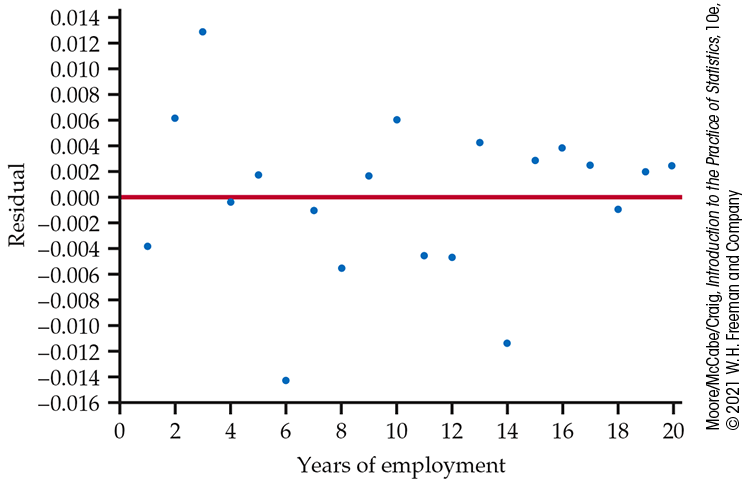
Figure 2.40 Plot of residuals, based on log salary, versus year for an individual who receives approximately a 5% raise each year for 20 years, Exercise 2.134.
-
-
2.135 Make some predictions. The individual whose salary we have been studying wants to do some financial planning. Specifically, she would like to predict her salary six years into the future—that is, for Year 26. She is willing to assume that her employment situation will be stable for the next six years and that it will be similar to the past 20 years.
-
Predict her salary for Year 26, using the least-squares regression equation constructed to predict salary from year.
-
Predict her salary for Year 26, using the least-squares regression equation constructed to predict log salary from year. Note that you will need to take the predicted log salary and convert this value back to the predicted salary. Many calculators have a function that will perform this operation.
-
Which prediction do you prefer: (a) or (b)? Explain your answer.
-
Someone looking at the numerical summaries and not the plots for these analyses says that because both models have very high values of
-
Discuss the value of graphical summaries and the problems of extrapolation using what you have learned in studying these salary data.
-
-
2.136 Faculty salaries. Here are the salaries for a sample of professors in a mathematics department at a large midwestern university for the academic years 2019–2020 and 2020–2021:

2019–2020 salary ($) 2020–2021 salary ($) 2019–2020 salary ($) 2020–2021 salary ($) 160,600 163,700 151,650 154,200 127,700 130,660 147,160 150,140 124,120 126,400 90,290 93,590 113,800 116,900 90,500 93,000 127,000 130,000 100,000 102,900 126,790 130,400 156,850 159,830 118,520 121,700 137,500 140,510 160,050 162,900 130,100 133,100 -
Construct a scatterplot with the 2020–2021 salaries on the vertical axis and the 2019–2020 salaries on the horizontal axis.
-
Comment on the form, direction, and strength of the relationship in your scatterplot.
-
What proportion of the variation in 2020–2021 salaries is explained by 2019–2020 salaries?
-
-
2.137 Find the line and examine the residuals. Refer to the previous exercise.
-
Find the least-squares regression line for predicting 2020–2021 salaries from 2019–2020 salaries.
-
Analyze the residuals, paying attention to any outliers or influential observations. Write a summary of your findings.
-
-
2.138 Bigger raises for those earning less. Refer to the previous two exercises. The 2019–2020 salaries do an excellent job of predicting the 2020–2021 salaries. Is there anything more that we can learn from these data? In this department, there is a tradition of giving higher-than-average percent raises to those whose salaries are lower. Let’s see if we can find evidence to support this idea in the data.
-
Compute the percent raise for each faculty member. Take the difference between the 2020–2021 salary and the 2019–2020 salary, divide by the 2019–2020 salary, and then multiply by 100. Make a scatterplot with raise as the response variable and the 2019–2020 salary as the explanatory variable. Describe the relationship that you see in your plot.
-
Find the least-squares regression line and add it to your plot.
-
Analyze the residuals. Are there any outliers or influential cases? Make a graphical display and include this in a short summary of your conclusions.
-
Is there evidence in the data to support the idea that greater percent raises are given to those with lower salaries? Include numerical and graphical summaries to support your conclusion.
-
-
2.139 Firefighters and fire damage. Someone says, “There is a strong positive correlation between the number of firefighters at a fire and the amount of damage the fire does. So sending lots of firefighters just causes more damage.” Explain why this reasoning is wrong.
-
2.140 Predicting text pages. The editor of a statistics text would like to plan for the next edition. A key variable is the number of pages that will be in the final version. Text files are prepared by the authors using a word processor called LaTeX, and separate files contain figures and tables. For the previous edition of the text, the number of pages in the LaTeX files can easily be determined, as well as the number of pages in the final version of the text. Here are the data:

Chapter 1 2 3 4 5 6 7 8 9 10 11 12 13 LaTeX pages 77 73 59 80 45 66 81 45 47 43 31 46 26 Text pages 99 89 61 82 47 68 87 45 53 50 36 52 19 Plot the data and describe the overall pattern.
-
Find the equation of the least-squares regression line and add the line to your plot.
-
Find the predicted number of text pages for a chapter in the next edition if the number of LaTeX pages is 52.
-
Write a short report for the editor explaining to her how you constructed the regression equation and how she could use it to estimate the number of pages in the next edition of the text.
-
 2.141 Plywood strength.
How strong is a building material such as plywood? To be specific,
support a 24-inch by 2-inch strip of plywood at both ends and
apply force in the middle until the strip breaks. The modulus of
rupture (MOR) is the force needed to break the strip. We would
like to be able to predict MOR without actually breaking the wood.
The modulus of elasticity (MOE) is found by bending the wood
without breaking it. Both MOE and MOR are measured in pounds per
square inch. Here are data for 32 specimens of the same type of
plywood:38
2.141 Plywood strength.
How strong is a building material such as plywood? To be specific,
support a 24-inch by 2-inch strip of plywood at both ends and
apply force in the middle until the strip breaks. The modulus of
rupture (MOR) is the force needed to break the strip. We would
like to be able to predict MOR without actually breaking the wood.
The modulus of elasticity (MOE) is found by bending the wood
without breaking it. Both MOE and MOR are measured in pounds per
square inch. Here are data for 32 specimens of the same type of
plywood:38

MOE MOR MOE MOR MOE MOR MOE MOR 2,005,400 11,591 1,774,850 10,541 2,181,910 12,702 1,747,010 11,794 1,166,360 8,542 1,457,020 10,314 1,559,700 11,209 1,791,150 11,413 1,842,180 12,750 1,959,590 11,983 2,372,660 12,799 2,535,170 13,920 2,088,370 14,512 1,720,930 10,232 1,580,930 12,062 1,355,720 9,286 1,615,070 9,244 1,355,960 8,395 1,879,900 11,357 1,646,010 8,814 1,938,440 11,904 1,411,210 10,654 1,594,750 8,889 1,472,310 6,326 2,047,700 11,208 1,842,630 10,223 1,558,770 11,565 1,488,440 9,214 2,037,520 12,004 1,984,690 13,499 2,212,310 15,317 2,349,090 13,645 Can we use MOE to predict MOR accurately? Use the data to write a discussion of this question.
-
2.142 Distribution of the residuals. Some statistical methods require that the residuals from a regression line have a distribution that is approximately Normal. The residuals for the education spending example are plotted in Example 2.33 (page 117). Is their distribution close to Normal? Make a Normal quantile plot to find out.

-
2.143 An example of Simpson’s paradox. Mountain View University has professional schools in business and law. Here is a three-way table of applicants to these professional schools, categorized by sex, school, and admission decision:39
Business Law Sex Admit Sex Admit Yes No Yes No Male 400 200 Male 90 110 Female 200 100 Female 200 200 -
Make a two-way table of sex by admission decision for the combined professional schools by summing entries in the three-way table.
-
From your two-way table, compute separately the percents of male and female applicants admitted. Male applicants are admitted to Mountain View’s professional schools at a higher rate than female applicants.
-
Now compute separately the percents of male and female applicants admitted by the business school and by the law school.
-
Explain carefully, as if speaking to a skeptical reporter, how it can happen that Mountain View appears to favor males when this is not true within each of the professional schools.
-
-
2.144 Simpson’s paradox and regression. Simpson’s paradox occurs when a relationship between variables within groups of observations reverses when all of the data are combined. The phenomenon is usually discussed in terms of categorical variables, but it also occurs in other settings. Here is an example:

y x Group y x Group 10.1 1 1 18.3 6 2 8.9 2 1 17.1 7 2 8.0 3 1 16.2 8 2 6.9 4 1 15.1 9 2 6.1 5 1 14.3 10 2 -
Make a scatterplot of the data for Group 1. Find the least-squares regression line and add it to your plot. Describe the relationship between y and x for Group 1.
Do the same for Group 2.
-
Make a scatterplot using all 10 observations. Find the least-squares regression line and add it to your plot.
-
Make a plot with all of the data using different symbols for the two groups. Include the three regression lines on the plot. Write a paragraph explaining how Simpson’s paradox is at work here, using this graphical display to illustrate your explanation.
-
-
2.145 Class size and class level.
A university classifies its classes as either “small” (fewer than
40 students) or “large.” A dean sees that 62% of Department A’s
classes are small, while Department B has only 40% small classes.
She wonders if she should cut Department A’s budget and insist on
larger classes. Department A responds to the dean by pointing out
that classes for third- and fourth-year students tend to be
smaller than classes for first- and second-year students. The
following three-way table gives the counts of classes by
department, size, and student audience. Write a short report for
the dean that summarizes these data. Start by computing the
percents of small classes in the two departments and include other
numerical and graphical comparisons, as needed. Here are the
numbers of classes to be analyzed:

Year Department A Department B Large Small Total Large Small Total First 2 0 2 18 2 20 Second 9 1 10 40 10 50 Third 5 15 20 4 16 20 Fourth 4 16 20 2 14 16 -
2.146 More smokers live at least 20 more years! You can see the headlines: “More smokers than nonsmokers live at least 20 more years after being contacted for study!” A medical study contacted randomly chosen people in a district in England. Here are data on the 1314 women contacted who were either current smokers or who had never smoked. The table classifies these women by their smoking status and age at the time of the survey and whether they were still alive 20 years later:40

Age 18 to 44 Age 45 to 64 Age 65+ Smoker Not Smoker Not Smoker Not Dead 19 13 78 52 42 165 Alive 269 327 167 147 7 28 -
From these data, make a two-way table of smoking (yes or no) by Dead or Alive. What percent of the smokers stayed alive for 20 years? What percent of the nonsmokers survived? It seems surprising that a higher percent of smokers stayed alive.
-
The age of the women at the time of the study is a lurking variable. Show that within each of the three age groups in the data, a higher percent of nonsmokers remained alive 20 years later. This is another example of Simpson’s paradox.
-
The study authors give this explanation: “Few of the older women (over 65 at the original survey) were smokers, but many of them had died by the time of follow-up.” Compare the percent of smokers in the three age groups to verify the explanation.
-
-
2.147 Recycled product quality. Recycling is supposed to save resources. Some people think recycled products are lower in quality than other products, a fact that makes recycling less practical. People who actually use a recycled product may have different opinions from those who don’t use it. Here are data on attitudes toward coffee filters made of recycled paper among people who do and don’t buy these filters:41

Think the quality of the recycled product is: Higher The same Lower Buyers 20 7 9 Nonbuyers 29 25 43 -
Find the marginal distribution of opinion about quality. Assuming that these people represent all users of coffee filters, what does this distribution tell us?
-
How do the opinions of buyers and nonbuyers differ? Use conditional distributions as a basis for your answer. Include a mosaic plot if you have access to the needed software. Can you conclude that using recycled filters causes more favorable opinions? If so, giving away samples might increase sales.
-
-
2.148 Averaged date for blueberries and anthocyanins.
Refer to
Exercises 2.8
and 2.30,
where you examined the variables Antho4 and Antho3. Report the
least-squares regression line, using Antho3 to predict Antho4.
Also report the correlation between these two variables. The
variables Antho4M and Antho3M were computed by averaging Antho4
and Antho3 for values in the intervals [0, 0.5), [0.5, 1.0), [1.0,
1.5), [1.5, 2.0), [2.0, 2.5), [2.5, 3.0), and [3.0, 3.5). Analyze
the relationship between Antho4M and Antho3M and compare these
results with what you found using Antho4 and Antho3. Summarize
what the comparison tells you about relationships with averaged
data.

-
2.149 Restricting the range for blueberries and anthocyanins.
Refer to
Exercises 2.8
and 2.30,
where you examined the variables Antho4 and Antho3. Report the
least-squares regression line, using Antho3 to predict Antho4.
Also report the correlation between these two variables. The data
file BERRIER was created from the data file BERRIES by excluding
cases with values of Antho3 that are less than 1.5 and cases with
values of Antho3 that are greater than 3. Analyze the relationship
between Antho4 and Antho3 for this restricted range data set, and
compare your results with what you found for the complete data
set. Summarize what the comparison tells you about relationships
with a restricted range.

PUTTING IT ALL TOGETHER
-
2.150 Survival and sex on the Titanic. In Exercise 2.100 (page 138), you examined the relationship between survival and class on the Titanic. The data file TITANIC contains data on the sex of the Titanic passengers. Examine the relationship between survival and sex and write a short summary of your findings.

-
2.151 Survival, class, and sex on the Titanic. Refer to the previous exercise and Exercise 2.100 (page 138). When we looked at survival and class, we ignored sex. When we looked at survival and sex, we ignored class. Are we missing something interesting about these data when we choose this approach to the analysis? Here is one way to answer this question.
-
Create two separate two-way tables: one for survival and class for the women and another for survival and class for the men.
-
Perform an analysis of the relationship between survival and class for the women. Summarize your findings.
-
Perform an analysis of the relationship between survival and class for the men. Summarize your findings.
-
Compare the analyses that you performed in parts (b) and (c). Write a short report on the relationship between survival and the two explanatory variables, class and sex.
-
-
2.152 Blueberries and anthocyanins. Refer to Exercises 1.122 and 1.123 (page 69), where you described the distributions of Antho3 and Antho4. Use Antho3 to predict Antho4. Write a summary of this relationship, using the methods and ideas that you learned in this chapter.

-
2.153 Blueberries and anthocyanins. Figure 2.41 gives JMP output for using Antho1 to predict Antho2. Use this output to write a summary of this relationship, using the methods and ideas that you learned in this chapter.
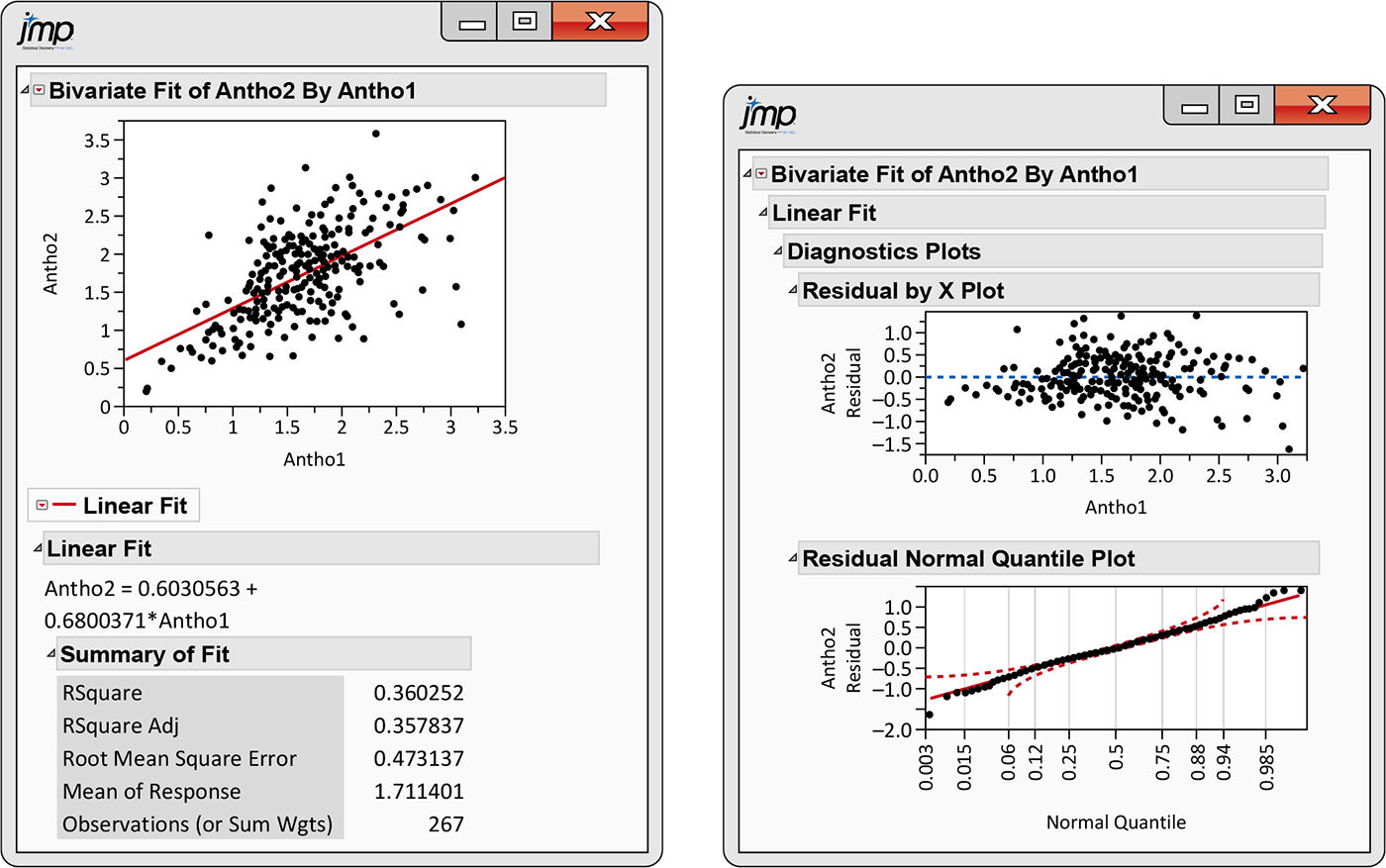
Figure 2.41 Selected JMP outputs for examining the relationship between Antho2 and Antho1, Exercise 2.153.