14.1 The Logistic Regression Model
Binomial distributions and odds
In Chapter 5 we studied binomial distributions, and in Chapter 8 we learned how to do statistical inference for the proportion p of successes in the binomial setting. We start with a brief review of some of these ideas that we will need in this chapter.
Example 14.1 Do you eat breakfast regularly?
A random sample of 300 students from your college was asked if they regularly eat breakfast. Of these students, 180 responded that they eat breakfast regularly.
Using the notation of
Chapter 5,
p is the proportion of students in the population of
students in your college who eat breakfast regularly. Assuming that
the population is much larger than the SRS of size n, the
number of students who would respond that they eat breakfast
regularly has the binomial distribution with parameters n and
p. For this survey, the sample size is
Based on this SRS, we estimate that 60% of the students at your college eat breakfast regularly.
Logistic regressions work with
odds
rather than proportions. The odds are simply the ratio of the
proportions for the two possible outcomes. If
A similar formula for the
population
odds
is obtained by substituting p for
Example 14.2 Odds of eating breakfast regularly.
For the breakfast eating data, the proportion of students who
responded that they eat breakfast regularly is
Therefore, the odds of eating breakfast regularly are
When people speak about odds, they often express odds using integers
or fractions. We calculated the odds as 1.5, but we could have also
expressed it as
Check-in
-
14.1 Odds of drawing an ace. If you deal one card from a standard deck, the probability that the card is an ace is
Find the odds of drawing an ace.
-
Find the odds of drawing a card that is not an ace.
-
14.2 Given the odds, find the probability. If you know the odds, you can find the probability by solving the odds equation for the probability. So,
Odds for two groups
In Example 8.11 (page 469) we compared the return rates of lost wallets with money and without money. Using the methods of Chapter 8, we compared the proportions of returned wallets with a confidence interval (page 470) and with a significance test (page 475).
Example 14.3 Comparing the returns of wallets with money and without money.
![]()
Figure 14.1
contains output from JMP for this comparison. The sample proportion
of returned wallets with money is given as 58%, and the sample
proportion for wallets with no money is 37%. These entries are the
row percents in the two-way table. The difference is 0.211, and the
95% confidence interval is (0.130715, 0.286504). We can summarize
this result by saying, “The percent of returned wallets with money
is 21% higher than the percent of wallets returned without money.
This difference is statistically significant
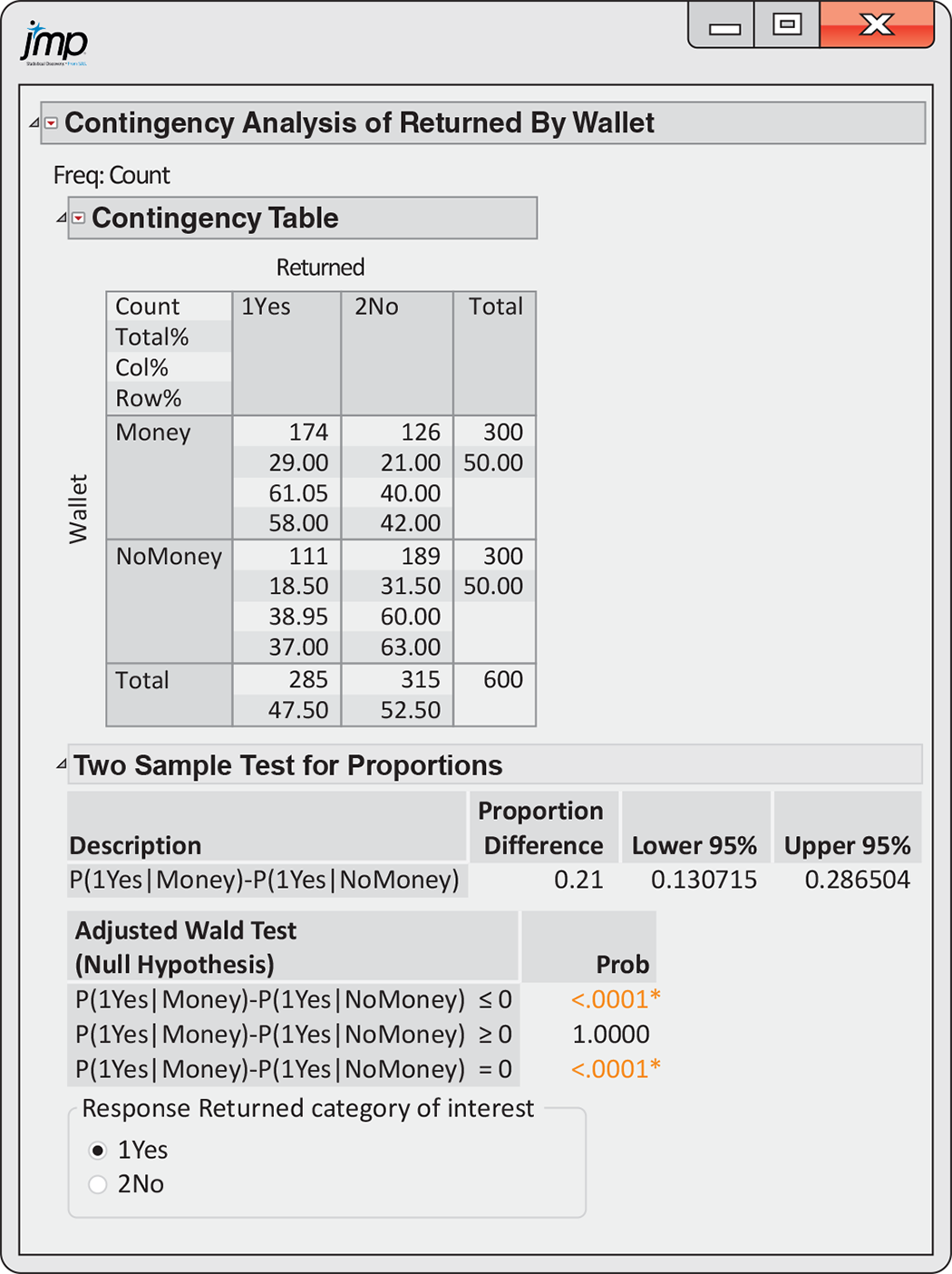
Figure 14.1 JMP output for the comparison of the proportions of returned wallets with money and with no money, Example 14.3.
We could also describe the difference in percents using odds.
Example 14.4 Odds for lost wallets being returned.
![]()
For wallets with money,
Similarly, for wallets without money we have
Check-in
-
14.3 Physical education requirements. In Exercise 8.41 (page 482) you examined the proportion in higher education institutions that had a physical education requirement. For the 225 private institutions, 60 had a requirement. For the 129 public universities, 101 had a requirement. Find the odds of having a physical education requirement for the private institutions. Do the same for the public institutions.
-
14.4 Find the odds. Refer to the previous Check-in question. Find the odds of not having a physical education requirement for the private institutions. Do the same for the public institutions.
Model for logistic regression
In simple linear regression, we modeled the mean
The logistic regression solution to this difficulty is to transform
the odds
Example 14.5 Log odds for lost wallets.
![]()
For wallets with money,
and for wallets without money,
For the lost wallets data, the explanatory variable is money, a categorical variable. To use a categorical explanatory variable in a logistic regression, we usually use a numerical code. We can do this with an indicator variable. For our problem, we will use an indicator of whether the wallet contains money:
We model the log odds as a linear function of the explanatory variable:
Note that the right-hand side of this equation is the same as the
function that we used for the mean of y in the simple linear
regression model (page 519).
Figure 14.2
graphs the relationship between p and x for some
different values of
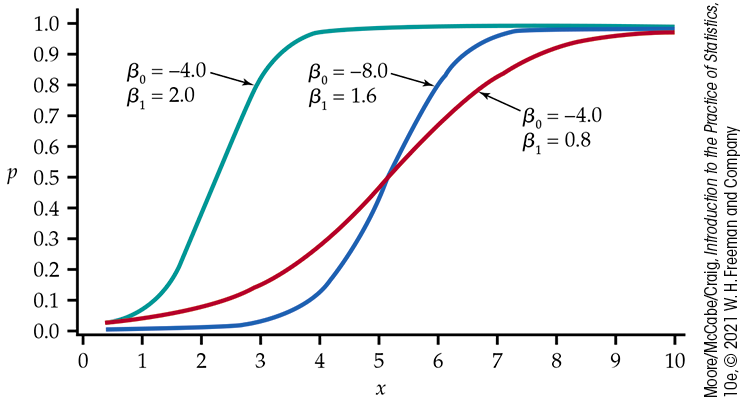
Figure 14.2 Plot of p versus x for different logistic regression models.
Check-in
-
14.5 Find the log odds. Refer to Check-in question 14.3. Find the log odds for having a physical education requirement for private institutions. Do the same for public institutions.
-
14.6 Find the log odds. Refer to Check-in question 14.4. Find the log odds for not having a physical education requirement for private institutions. Do the same for public institutions.
In Chapter 10 we
studied inference for simple linear regression, a model with one
explanatory variable x. In
Chapter 11, we
extended the model to the case where there can be several explanatory
variables,
As we did with least-squares regression, we use the term simple logistic regression for models with a single explanatory variable and multiple logistic regression for models with more than one explanatory variable. In the latter case, each regression coefficient expresses the effect of the variable when all other explanatory variables are held constant.
Example 14.6 Model for lost wallets.
![]()
For our lost wallets example, there are
The logistic regression model specifies the relationship between p and x. Because there are only two values for x, we write both equations. For wallets with money,
and for wallets without money,
Note that there is a
Logistic regression with an indicator explanatory variable is a very special case. It is important because many multiple logistic regression analyses focus on one or more such variables as the primary explanatory variables of interest. For now, we use this special case to understand a little more about the model.
Fitting and interpreting the logistic regression model
In general, the calculations needed to find the estimates
Example 14.7 Log odds
and
b 1
![]()
In Example 14.5, we found the log odds for wallets with money,
and for wallets without money,
The logistic regression model for money is
and for no money, it is
To find the estimates
and the estimate of
The fitted logistic regression model is
The coefficient
The transformation
Example 14.8 Odds ratio for lost wallets.
![]()
For the lost wallet data, the odds ratio is the odds that a wallet
with money
We can multiply the odds for without money by the odds ratio to obtain the odds for with money:
In this case, we would say that the odds for with money are about two and a third times the odds for without money.
Notice that we have chosen the coding for the indicator variable so
that the regression coefficient
Logistic regression with an explanatory variable having two values is a very important special case. Here is an example where the explanatory variable is quantitative.
Example 14.9 Is a movie going to be profitable?
![]()
The MOVIES data file includes both the movie’s budget and the total
U.S. revenue for 76 movies. For this example, we will classify each
movie as profitable
where p is the probability that the movie is profitable and x is the log opening-weekend revenue. The model for estimated log odds fitted by software is
The odds ratio is
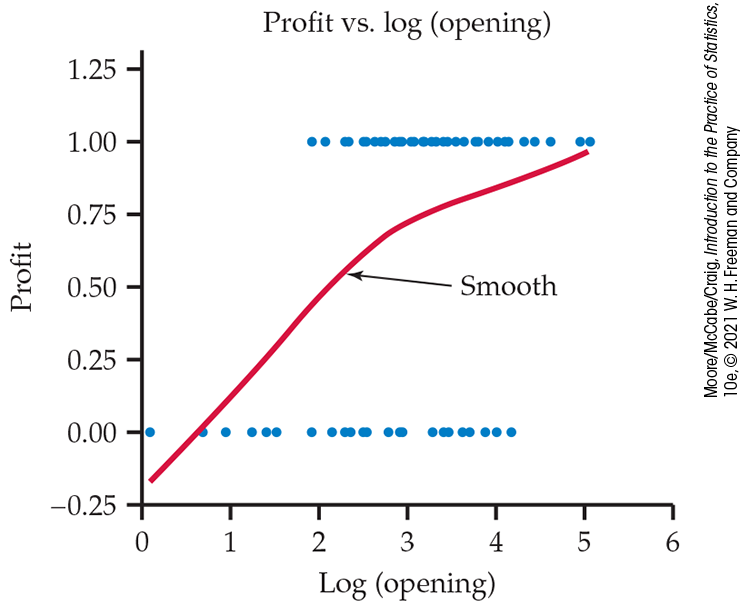
Figure 14.3 Scatterplot of profit
Check-in
-
14.7 Find the logistic regression equation and the odds ratio. Refer to Check-in questions 14.3 and 14.5. Find the logistic regression equation and the odds ratio.
-
14.8 Find the logistic regression equation and the odds ratio. Refer to Check-in questions 14.4 and 14.6. Find the logistic regression equation and the odds ratio.
Section 14.1 SUMMARY
-
If
-
The logistic regression model relates the log odds or logit to the explanatory variables:
Here p is a binomial proportion of successes, and
-
The parameters of the logistic regression model are
-
For the explanatory variable
Section 14.1 EXERCISES
-
14.1 What purchases will be made? A poll of 1200 adults aged 18 or older asked about purchases they intended to make for the upcoming holiday season. A total of 543 adults listed gift card as a planned purchase.
-
What proportion of adults plan to purchase a gift card as a present?
-
What are the odds that an adult will purchase a gift card as a present?
-
What proportion of adults do not plan to purchase a gift card as a present?
-
What are the odds that an adult will not buy a gift card as a present?
-
How are your answers to parts (b) and (d) related?
-
-
14.2 How did you use your cell phone? One question in a Pew Internet Poll on cell phone use asked whether, during the past 30 days, the person had used their phone while in a store to call a friend or family member for advice about a purchase they were considering. The poll surveyed 1003 adults living in the United States. Of these, 462 responded that they had used their cell phones for this purpose.2
-
What proportion of those surveyed reported that they used their cell phones while in a store within the past 30 days to call a friend or family member for advice about a purchase they were considering?
-
Find the odds for using the phone for the purpose in part (a).
-
-
14.3 Find some odds. For each of the following probabilities, find the odds: 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9. Make a plot of the odds versus the probabilities and describe the relationship.
-
14.4 A logistic regression for teeth and military service. Exercise 8.40 (page 481) describes data on the numbers of U.S. recruits who were rejected for service in a war against Spain because they did not have enough teeth. The exercise compared the rejection rate for recruits who were under the age of 20 with the rate for those who were 40 or over. To run a logistic regression for this setting, we define an indicator explanatory variable

-
How many recruits were examined? How many were rejected, and how many were not rejected?
Write the fitted logistic regression model.
-
Demonstrate how to obtain the odds ratio from the table of coefficients.
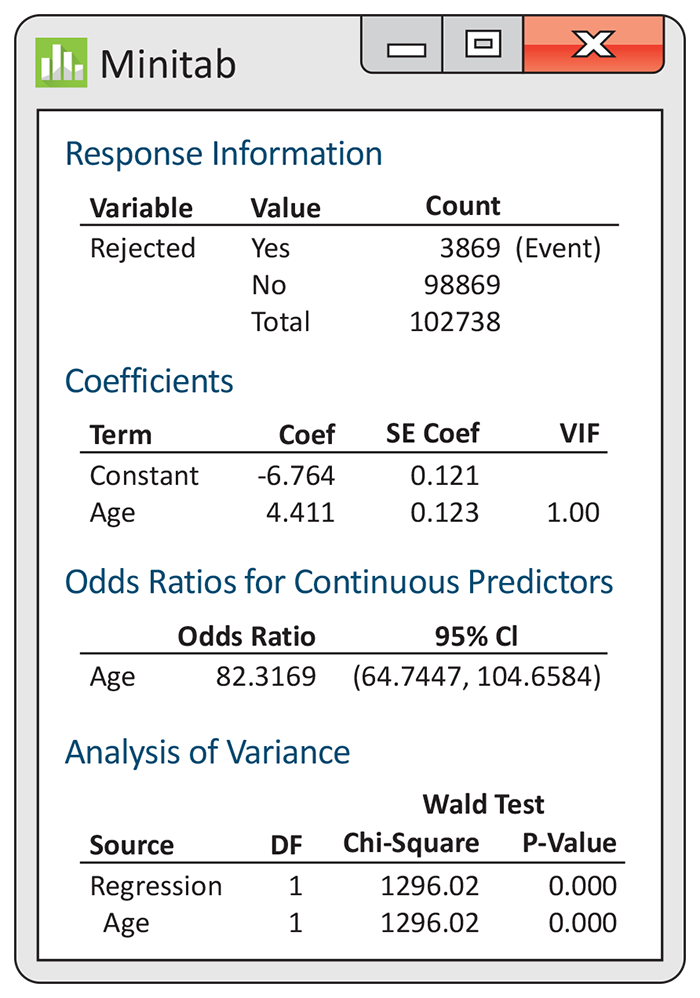
Figure 14.4 Minitab logistic regression output for predicting recruit rejection using age in two categories, for Exercises 14.4, 14.13, 14.15, and 14.22.
-
-
14.5 A logistic model for cell phones. Refer to Exercise 14.2. Suppose that you want to investigate differences in cell phone use among customers of different ages. You create an indicator explanatory variable x that has the value 1 if the customer is 25 years of age or less and 0 if the customer over 25 years of age.
-
Describe the statistical model for logistic regression in this setting.
-
Explain the relationship between the regression coefficients and the odds ratios for the two groups of customers defined by x.
-
-
14.6 High blood pressure and cardiovascular disease. There is much evidence that high blood pressure is associated with increased risk of death from cardiovascular disease. A major study of this association examined 3351 men with high blood pressure and 2654 men with low blood pressure. During the period of the study, 20 men in the low-blood-pressure group and 57 in the high-blood-pressure group died from cardiovascular disease.
-
Find the proportion of men who died from cardiovascular disease in the high-blood-pressure group. Then calculate the odds.
Do the same for the low-blood-pressure group.
-
Now calculate the odds ratio with the odds for the high-blood-pressure group in the numerator. Describe the result in words.
-
-
14.7 What’s wrong? For each of the following, explain what is wrong and why.
-
The intercept
-
The log odds of an event are 1 minus the probability of the event.
-
If
-
-
14.8 Will a movie be profitable? In Example 14.9 (page 14-9), we described a model to predict whether a movie is profitable based on log opening-weekend revenue
-
-
14.9 Convert the odds to probabilities. Refer to the previous exercise. For each opening-weekend revenue, compute the estimated probability that the movie is profitable.
-
14.10 Salt intake and cardiovascular disease. In Example 9.13 (page 501), the relative risk of developing cardiovascular disease (CVD) for people with low- and high-salt diets was estimated. Let’s reanalyze these data using the methods in this chapter. Here are the data:
Developed CVD Salt in diet Low High Total Yes 88 112 200 No 1081 1134 2215 Total 1169 1246 2415 -
For each salt level, find the probability of developing CVD.
-
Convert each of the probabilities that you found in part (a) to odds.
-
Find the log of each of the odds that you found in part (b).
-
-
14.11 Salt in the diet and CVD. Refer to the previous exercise. Use
-
Find the estimates
Give the fitted logistic regression model.
-
What is the odds ratio for a high-salt versus low-salt diet?
-
When the probability of an event is very small, the odds ratio and relative risk are similar. Compare this odds ratio with the relative risk estimate in Example 9.13. Are they close? Explain your answer.
-
-
 14.12 Internet use in Canada. A recent study
used data from the Canadian Internet Use Survey (CIUS) to
explore the relationship between certain A variables and
Internet use by individuals in Canada.3
The response variable refers to the use of the Internet from any
location within the last 12 months. Explanatory variables
included Age (years), Income (thousands of dollars), Location
14.12 Internet use in Canada. A recent study
used data from the Canadian Internet Use Survey (CIUS) to
explore the relationship between certain A variables and
Internet use by individuals in Canada.3
The response variable refers to the use of the Internet from any
location within the last 12 months. Explanatory variables
included Age (years), Income (thousands of dollars), Location
Explanatory variable b Age Income 0.013 Location 0.367 Sex Education 1.080 Language 0.285 Children 0.049 Intercept 2.010 All but Children were significant at the 0.05 level.
-
Interpret the sign of each of the coefficients (except the intercept) in terms of the probability that the individual uses the Internet.
-
Compute the odds ratio for each of the variables in the table.
-
What are the odds that a French-speaking, 23-year-old male, living alone in Montreal and making $50,000 a year his second year after college is using the Internet?
Convert the odds in part (c) to a probability.
-