Chapter 16 CHECK-IN QUESTIONS
-
16.1 Answers will vary.
-
- Answers will vary based on the mean calculated in 16.1.
- 1.20.
- (5.34, 10.34).
-
-
Based on 2000 resamples,
- The bootstrap distribution looks reasonably Normal, with a little bias.
- The t interval is 1.2 to 18.7.
-
Based on 2000 resamples,
-
- For the 99% bootstrap percentile confidence interval, there is 0.5% on either end, so we need the 0.5 percentile and 99.5 percentile. For the 90% bootstrap percentile confidence interval, we need the 5th percentile and the 95th percentile.
-
16.9 No, because we believe that one population has a smaller variability. In order to pool the data, the permutation test requires that both populations be the same when
Chapter 16 EXERCISES
-
-
The standard deviation of the bootstrap distribution will be
approximately
- Bootstrap samples are done with replacement from the original sample.
- You should use a sample size equal to the original sample size.
- The bootstrap distribution is created by sampling with replacement from the original sample, not the population.
-
The standard deviation of the bootstrap distribution will be
approximately
-
- Answers will vary, but a Normal quantile plot indicates that it is roughly Normal.
- Answers will vary.
- The means could range from 24 to 140, but based on 2000 resamples, the means should range between 33 and 122.
- Answers will vary, but based on 2000 sets of five bootstrap samples, the error should vary between 3.5 and 28.8.
-
16.5 The sampling distribution is approximately Normal, with the mean of the bootstrap distribution around 78.
-
16.7 The mean of the original sample is 74.6667; the mean of the bootstrap distribution is 0.1047778 higher. The bootstrap standard error is 14.9482.
-
16.9 The bootstrap appears Normal.
-
16.11 The bootstrap appears Normal.
-
16.13 The bootstrap standard errors will vary.
-
- The larger resamples are closer to Normal.
- The standard error is larger for the smaller SRS because with the smaller sample sizes, there is more variability.
-
- We use the bootstrap t interval when the bias is small, not when it is large.
- Here, we can use the bootstrap t interval.
- (c–d) Do not use the bootstrap t interval when the bootstrap distribution is clearly skewed.
-
- Answers will vary.
-
- The bootstrap distribution looks reasonably Normal.
- (51.1169, 73.0831).
-
-
16.23 The bootstrap distribution of the standard deviation looks quite Normal. This particular resample had
-
- The data appear to be roughly Normal though with the typical random gaps and bunches that usually occur with relatively small samples. It appears from both the histogram and quantile plot that the mean is slightly larger than zero, but the difference is not large enough to rule out the N(0,1) distribution.
- The bootstrap distribution is extremely close to Normal, with no appreciable bias.
-
The typical SE is 0.1308, and the t interval is
-
-
- 0.3721.
- The standard error is much smaller than the standard deviation of the sample.
- Yes.
-
-
-
The distribution of
-
-
For
-
The distribution of
-
16.31 Answers will vary.
-
16.33 The bootstrap distribution is right-skewed; an interval based on t would not be appropriate. The original sample had the statistic of interest
-
- The bootstrap percentile and t intervals are very similar, suggesting that the t intervals are acceptable.
- Every interval (percentile and t) includes 0.
-
16.37 The results of the bootstrap interval may have a slightly larger standard error and also may have slightly higher bias.
-
16.39 One set of 1000 repetitions gave the BCa interval as (0.4503, 0.8049). We see the bootstrap distribution is left-skewed and that there was one possible high outlier as well. The lower end of the BCa interval typically varies between 0.42 and 0.46, while the upper end varies between 0.795 and 0.805. These intervals are lower than those found in the earlier example.
-
16.43 Answers will vary, but the confidence intervals will be wider with smaller sample sizes.
-
16.45 Typical ranges for the endpoints of the BCa interval (using males–females) are given below. This interval is comparable to the
Typical ranges BCa lower BCa upper 0.087 to 0.133 -
- Answers will vary. The shape is roughly Normal, with a small bias. Simple bootstrap inference can be used.
- Answers will vary. The confidence intervals should be close.
-
-
The regression line is
- The ends of the bootstrap distribution do not look very Normal; a t interval may not be appropriate.
-
The typical standard error of the slope is 0.2846. With
-
The regression line is
-
-
The distribution of the slope
-
The bootstrap confidence interval is
-
The distribution of the slope
-
16.53 Enter the data with the score given to the phone and an indicator for each design. We have hypotheses
-
16.55 If there is no relationship, we have
-
- The observed difference in means is 18.5.
- (b–c) Answers will vary.
-
Out of 20 resamples, the number that yield a difference of 18.5
(or more) have a binomial distribution with
-
Only one resample possibility can give a difference of means
greater than or equal to the observed value, so the exact
P-value is
-
-
-
-
- Answers will vary.
-
-
- The two populations should be the same shape but skewed (or otherwise clearly non-Normal) so that the t test is not appropriate.
- Either test is appropriate if the two populations are both Normal with the same standard deviation.
- We can use a t test but not a permutation test if both populations are Normal with different standard deviations.
-
-
We test
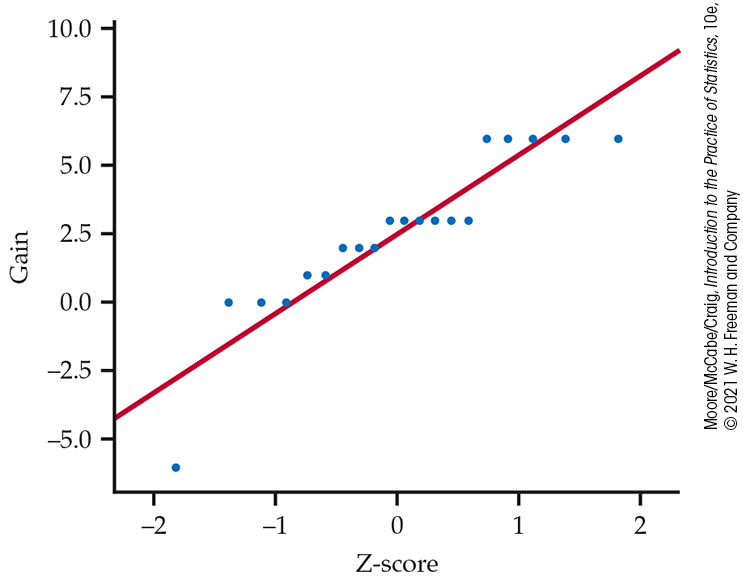
- The Normal quantile plot (right) looks odd because we have a small sample, and all differences are integers.
-
The P-value is almost always less than 0.002. Both tests lead to the same conclusion: The difference is statistically significant (that is, the language institute did help comprehension).
-
We test
-
-
We have
-
The observed correlation is
-
We have
-
16.67 For testing
-
16.69 For the permutation test, we must resample in a way that is consistent with the null hypothesis. Hence, we pool the data—assuming that the two populations are the same—and draw samples (without replacement) for each group from the pooled data. For the bootstrap, we do not assume that the two populations are the same, so we sample (with replacement) from each of the two data sets separately rather than pool the data first.
-
-
We will test
-
We test
-
We will test
-
16.73 The 95% t interval is narrower in some cases than the percentile interval. In Example 16.8, the percentile interval was 2.793 to 3.095 (a bit narrower and higher than the bootstrap confidence intervals), and the t interval was 2.80 to 3.10 (again, narrower and higher). This is at least in part explained by eliminating more observations on either end with the 25% trim.
-
- The correlation for males is 0.4657. Because the bootstrap distribution does not look Normal, we focus on the percentile interval. The lower end of the percentile intervals ranged from 0.269 to 0.286, with the upper end ranging from 0.623 to 0.625.
- The correlation for females is 0.3649. Again focusing on the percentile interval, the intervals are wider. The low end of the percentile interval ranged from 0.053 to 0.081, while the upper end ranged from 0.581 to 0.604.
-
The plot shows that the bootstrap distribution of the
differences in correlations is very Normal. It is also clear
that 0 will be included in the interval; the interval for this
bootstrap set was
-
16.77 The bootstrap distribution looks quite Normal, and (as a consequence) all of the bootstrap confidence intervals are similar to each other and also are similar to the standard (large-sample) confidence interval.
-
-
There were 32 poets who died at an average age of 63.19 years
-
Using a two-sample t test, we find that testing
- The bootstrap distribution is symmetric and seems close to Normal, except at the ends of the distribution, so a bootstrap t interval should be appropriate. The low ends of the bootstrap interval are typically between 5.26 and 5.82; the high ends are typically between 21.26 and 22.15. One particular interval seen was (5.40, 21.36). Note that this interval is a bit narrower than the two-sample t interval.
-
There were 32 poets who died at an average age of 63.19 years
-
16.81 The R permutation test for the mean ages returns a P-value of 0.006 (comparable to the 0.002 from the t test) in this instance. The 99% confidence interval for the P-value is between 0.0002 and 0.0185. We can determine that there is a difference in mean age at death between poets and nonfiction writers.
-
16.83 All answers (including the shape of the bootstrap distribution) will depend strongly on the initial sample of uniform random numbers. The median M of these initial samples will be between about 0.36 and 0.64 about 95% of the time; this is the center of the bootstrap t confidence interval.
- For a uniform distribution of 0 to 1, the population median is 0.5.
- Most of the time, the bootstrap distribution is quite non-Normal.
-
-
The more sophisticated BCa and tilting intervals may or may not
be similar to the bootstrap t interval. The
t interval is not appropriate because of the non-Normal
shape of the bootstrap distribution and because
-
16.85 Answers will vary.
-
- The 33% is the middle value from the confidence interval.
- (b–c) Answers will vary.
-
-
The standard test of
- The permutation P-value is typically between 0.02 and 0.03.
- The P-values are similar, even though, technically, the permutation test is significant at the 5% level, while the standard test is (barely) not. Because the samples are too small to assess Normality, the permutation test is safer. (In fact, the population distributions are discrete, so they cannot follow Normal distributions.)
-
The standard test of
-
- The mean ratio is 1.0596; the usual t interval is 1.0063 to 1.1128. The bootstrap distribution for the mean is close to Normal, and the bootstrap confidence intervals are usually similar to the usual t interval but slightly narrower. Bootstrapping the median produces a clearly non-Normal distribution; the bootstrap t interval should not be used for the median.
- The ratio of means is 1.0656; the bootstrap distribution is noticeably skewed, so the bootstrap t is not a good choice, but the other methods usually give intervals similar to 0.75 to 1.55.
- For example, the usual t interval from part (a) could be summarized by the statement “On average, Jocko’s estimates are 1% to 11% higher than those from other garages.”